Tableau と Python を併用して TabPy で処方的分析を行う方法



このブログ投稿は、元々 Medium に掲載されていたものです。
TabPy は Python パッケージであり、その場で Python コードを実行し、Tableau ビジュアライゼーションに結果を表示できるため、高度な分析アプリケーションをすばやく導入できます。TabPy が提供する分割アプローチによって、強力なデータサイエンスアルゴリズムに裏打ちされた、業界最高クラスの主要なデータビジュアライゼーション機能の 2 つの利用が可能となります。Tableau で Python アルゴリズムを利用できるようにすることの大きなメリットの 1 つは、ユーザーがパラメーターを調整し、ダッシュボードの更新時に、リアルタイムで分析への影響を評価できることです。
これを可能にするために、TabPy では主に、現在のビジュアライゼーションに基づいてデータが集計され、調整パラメーターが両方とも Python に転送されるという入出力アプローチを採用しています。データが処理され、出力が Tableau に返されて、現在のビジュアライゼーションが更新されます。ここでは、計算の基礎となる完全なデータセットが必要である一方で、ダッシュボードにメジャーの集計が表示されている、または複数レベルの集計を同時に表示したいとします。また、ダッシュボードの応答性を損なうことなく、1 回の計算で複数のデータソースを使用したいと考えるかもしれません。
この投稿では、以下のシナリオに基づいて、TabPy のパワーを最大限に引き出すのに役立つアプローチを紹介します。
- リアルタイムのインタラクション: リアルタイムのユーザーインターフェイスを使用して、処理時間だけでなく、パラメーターの変更とビジュアライゼーションの更新における遅延を最小限に抑える必要がある場合。
- 複数レベルの集計: 同じ Tableau ダッシュボードに (さまざまな) 集計レベルを表示したい一方で、すべての情報を網羅した最も精度の高い詳細なレベルで、すべての計算を実行する必要がある場合。
- さまざまなデータソース: バックエンドの計算が複数のデータソースやデータベースに依存している場合。
- Tableau と Python の間で転送されるデータ: 最適化の各段階で大量のデータが必要になるため、Tableau と Python バックエンドの間で多数のデータを転送する必要がある場合。
処方的分析を行うための TabPy の新しいアプローチ: 段階的な手順
Python と TabPy の両方がすでにインストールされていると仮定して、TabPy を実装するには、次の 3 つの手順を実行する必要があります。
この 3 つの手順を説明するために、製品ポートフォリオの最適化による複雑さの軽減について、使用事例をまとめました。
使用事例: 複雑さの軽減
最適化の対象は、主に合併と買収 (M&A) を通じて成長した B2B 販売業者です。このような無機的成長により、販売業者の業務構造は非常に複雑になっています。複数の市場で事業を展開しており、複数のカテゴリーやサブカテゴリーに分類された、数千の SKU (在庫管理単位) で構成されるポートフォリオを使用しています。さらに事態を複雑化しているのは、SKU がさまざまな工場で生産されていることです。
企業の経営陣は、最も収益性の低い SKU を除外することで利益率を高めたいと考えていますが、特定の市場シェアを維持するために、利益の低い製品の販売を続けるつもりです。また、目標資産稼働率を超えて、生産工場を稼働させ続けようとしています。稼働率を下げすぎると、各工場の固定費ベースに悪影響を及ぼすことを認識しているためです。
この例で参照できるデータは、年間の数量、コスト、収益を報告する SKU レベルのデータベースです。SKU は、カテゴリーとサブカテゴリーの階層レベルで見やすく表示されます。
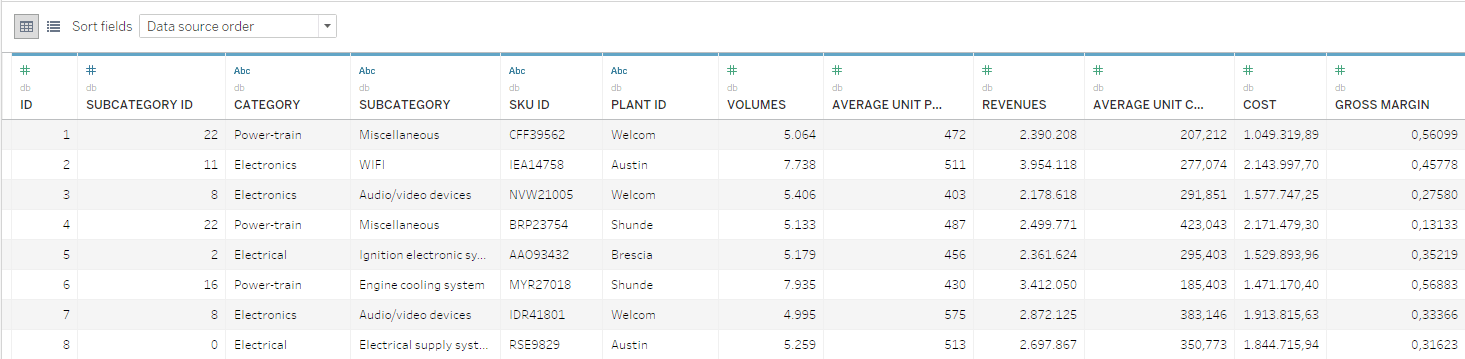
数学的な観点から見ると、経営陣が直面している製品ポートフォリオの最適化に関する課題は、非常にわかりやすいと言えます。ただし、最適化では、あらゆる戦略の意図も考慮して、情報に基づいた意思決定に必要な情報とツールにアクセスできる、幅広い関係者に参加してもらう必要があります。
これらの要件はすべて、以下で説明する TabPy アプローチによって達成できます。
1.Tableau ダッシュボードの試用版を準備する
まず、解決しなければならない問題に合わせて、調整することが重要です。この例では、シンプルな最適化アルゴリズムにより、SKU レベルで評価された総利益に基づいて、SKU が除外されます。
-
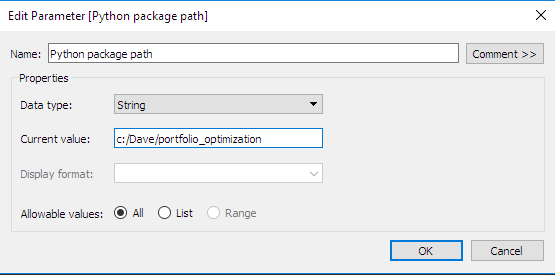
Tableau でインタラクティブなパラメーターを定義する: ここでは、2 つ目に便利なパラメーターを定義しました。これは、最適化ルーチンを含む Python パッケージが保存されるディレクトリになります。次のセクションで説明しますが、このタイプのパラメーターは、カスタム計算を定義する際に非常に役立ちます。
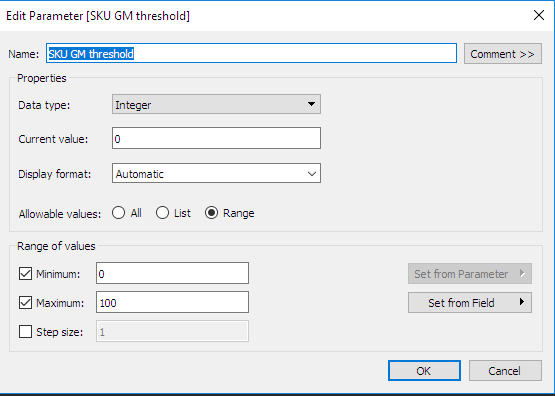
- 集計のビュー / レベルを定義する: ここでは、SKU レベルとサブカテゴリーレベルの 2 つの集計レベルを定義します。集計レベルの定義は、Python バックエンド関数の署名を規定するため重要です。各計算および集計レベルについて、1 つの特定の関数を定義する必要があります。集計レベルごとに、最適化された利益率、最適化された収益、最適化された数量のパラメーターを定義する必要があります。
-
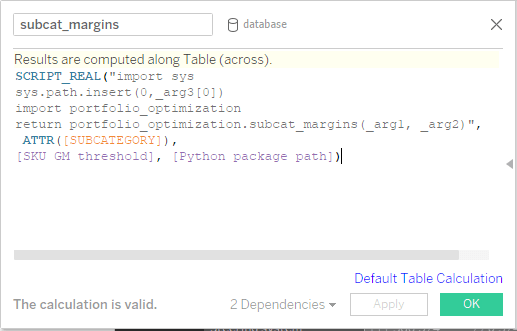
Tableau で計算フック (コールバック) を定義する: 入力パラメーター、集計レベル、必要な出力計算を定義したら、カスタム計算を定義できます。便宜上、最適化ルーチンはすべて、portfolio_optimization の Python パッケージで構造化されています。このパッケージでは、特定の集計レベルに対して選択された数量を返す関数を定義しています。先ほど定義したパラメーター (Python パッケージのパス) が関数に渡され、スクリプトで使用されて、ポートフォリオ最適化パッケージの保存場所を通知します。さらに、現在の集計レベルのインデクサー (サブカテゴリー集計レベルやサブカテゴリー自体など) は、常に Python バックエンドに渡され、結果が適切な順序で返されるようにします。入力パラメーターである SKU GM のしきい値も渡されます。
2.Python で計算ルーチンのバックエンドを作成する
Python バックエンドは、実行のコンテキストに基づいてグループ化された 2 つの関数クラスに分割されます。1 回実行された関数と、複数回繰り返された関数です。前者のクラスは、データベースの抽出や、変換および読み込み操作などです。このような機能は「1 回限りの操作」と呼ばれます。その逆がすべての Tableau コールバックのように、複数回繰り返される関数です。
- 1 回限りの操作: この例では、スクリプトが初めて実行される際に、データベースが 1 度だけ読み込まれます。このデータベースは、他のすべての関数で使用できるようになり、グローバル変数に格納されます。Python では、データベースがすでに読み込まれているかどうかを検出するために、ローカルネームスペースで既存のコピーをチェックします。この予防措置がなければ、Tableau が計算をリクエストするたびにデータベースが読み込まれ、実行速度が低下するおそれがあります。
- Tableau コールバック: 過去に定義されたすべてのフックには、それに対応する関数が必要です。ここでは、収益、数量、利益率の個別の計算を提供して、関数の入力として渡されたインデクサーを使用し、最適化の結果を集計するために使用される Pandas groupby 関数のインデックスを作成します。なお、コールバックには、実行速度を向上させるために、パラメーター変更検出機能が実装されています。パラメーターが変更され、その結果がグローバル変数を使用するすべてのコールバックで利用できるようになる場合にのみ、新しい最適化が生成されます。パラメーターの変更の検出は、前回の実行での値の保存に使用される、永続変数を通じて実装されます。このアプローチにより、コストがかかる操作を最小限に抑えられるため、実行速度が向上します。
3.Tableau フロントエンドを設計する
ここまでの手順によって、集計レベル、調整するパラメーター、計算バックエンドによって返される出力列など、すべての基本要素が定義されました。
最適化について説明しやすくするために、最適化プロセスの前後のポートフォリオを示す、2 つのワークシートをそれぞれ定義します。2 つのワークシートを並べて表示します。
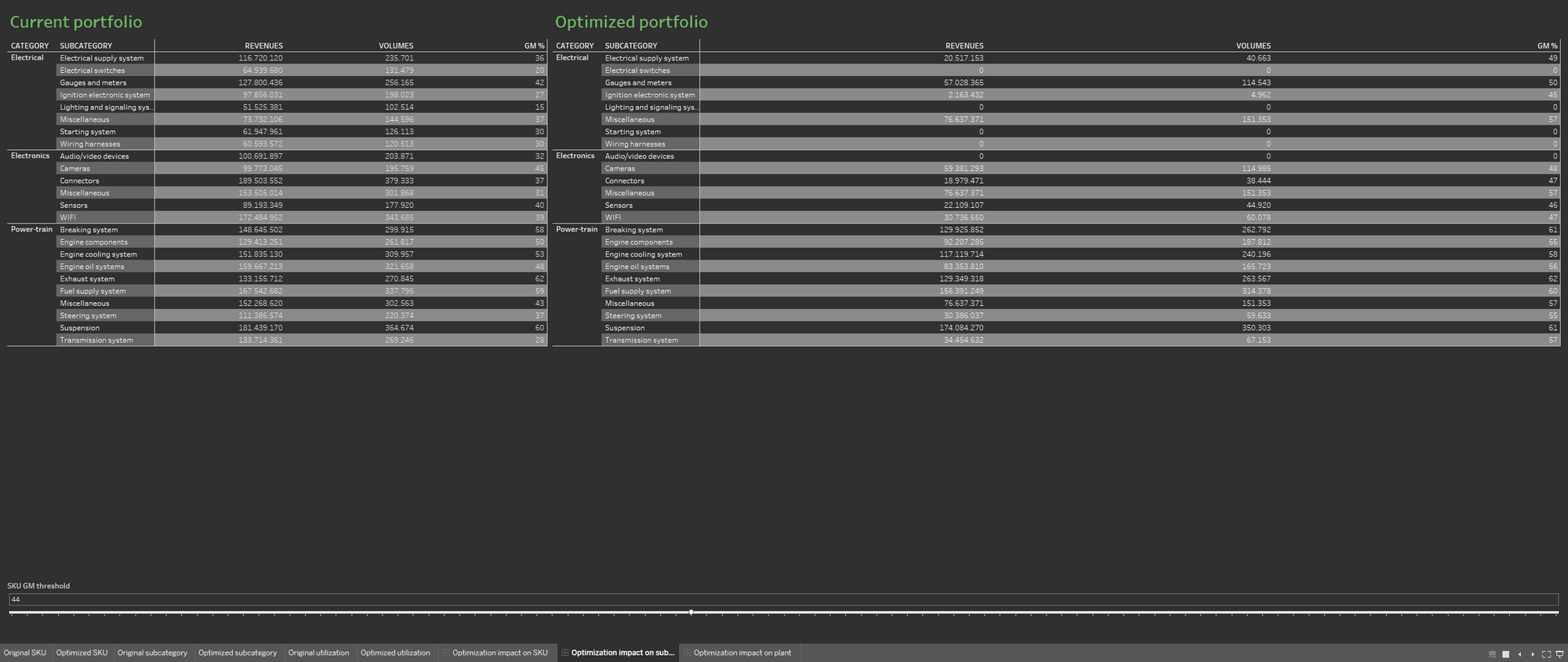
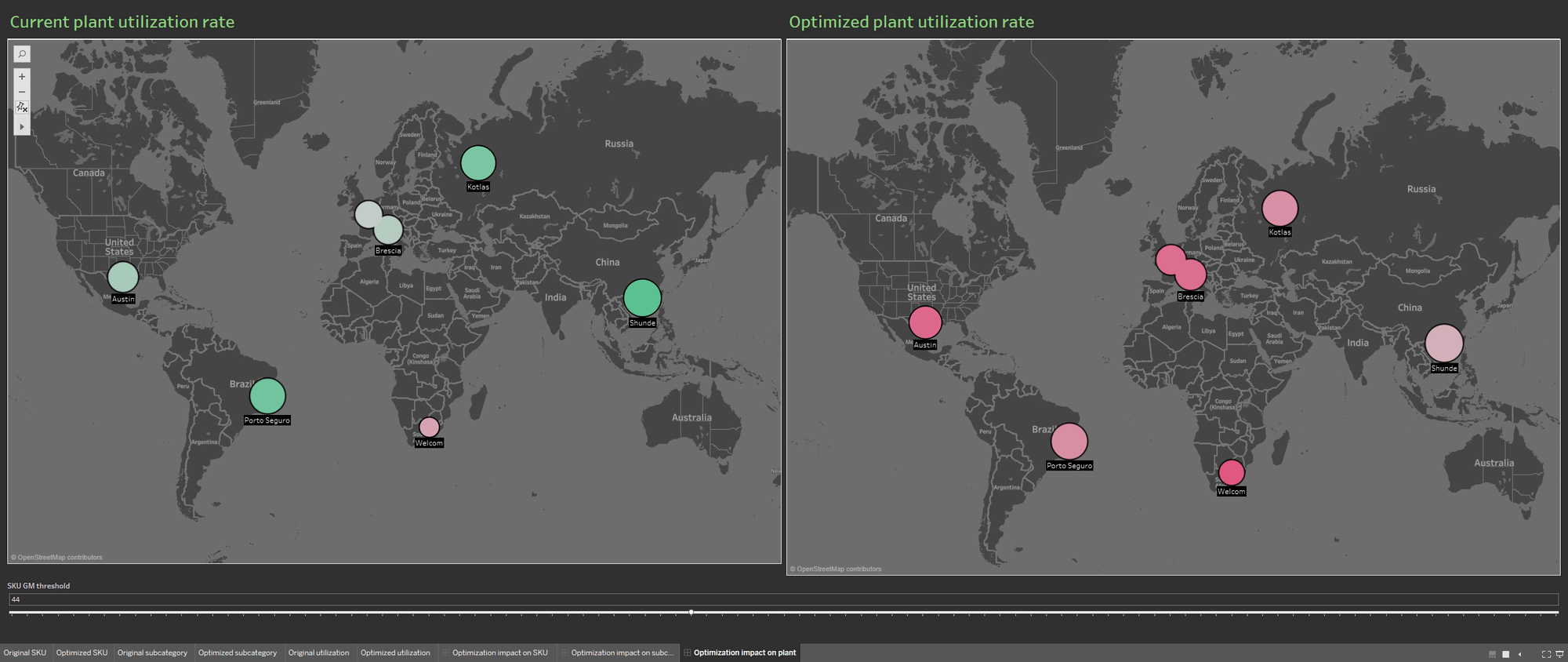
複数のデータソースを利用できるため、現在の工場稼働率と、最適化されたポートフォリオから算出した稼働率に関する情報をビジュアライゼーションに取り込み、ポートフォリオのデータベースを充実させることができます。繰り返しますが、最適化が生産工場に与える影響をわかりやすく説明するために、2 つの情報のビジュアライゼーションを並べています。
チームで TabPy を使用することによるメリット
この斬新なアプローチは、チームが強力なデータサイエンス手法を活用して、リアルタイムでやり取りできるという、重要なビジネス価値をもたらすだけでなく、バックエンドにも大きなメリットを提供します。他の多くのデータビジュアライゼーション手法では、プロセス全体を通じて、データサイエンティストに参加してもらう必要があり、コストも嵩みます。ですが、このアプローチでは、Tableau ダッシュボードの試用版を準備して、バックエンドの Python 計算ルーチンを作成する際にのみ、データサイエンティストのリソースが必要となります。Tableau の使いやすさにより、幅広いリソースを使用して、フロントエンドを設計し、エンドユーザーでテストして、保守まで行えます。
通常、フロントエンドの設計時には、エンドユーザーとの複数回にわたるディスカッションなど、時間のかかる反復的なプロセスが生じます。TabPy の新しいアプローチでは、プロジェクトの実行中に、マネージャーがチーム構成を変更できるようにすることで、コスト効率を大幅に改善できます。また、このアプローチにより、基盤となるバックエンドの再利用性を向上して、幅広いユーザーが特定のコンテキスト、対象者、状況に合わせて、Tableau で独自のカスタムダッシュボードを構築できるようになります。計算ロジックと基盤となる基本要素の再利用は、データビジュアライゼーションの全体的なコストを改善できる別の方法にもなっています。
この例をさらに掘り下げるには、こちらから Tableau ダッシュボードと Python バックエンドを入手いただけます。このアプローチに関する詳細については、公式の TabPy Github リポジトリや Tableau コミュニティのスレッドを参照してください。
関連ストーリー

VizQL Data Service: Extend Your Data Beyond Visualizations
 2025/03/19
2025/03/19

VizQL Data Service from Tableau: Use Your Data, Your Way
 2024/08/08
2024/08/08

When and How to Use Multi-fact Relationships in Tableau
 2024/08/01
2024/08/01
Subscribe to our blog
Tableau の最新情報をメールでお知らせします