Utilisation conjointe de Tableau et de Python pour exploiter l'analytique prescriptive avec TabPy



Cet article de blog a d'abord été publié sur Medium.
TabPy est un package Python vous permettant d'exécuter du code Python à la volée et d'afficher vos résultats dans des visualisations Tableau. Grâce à cet outil, vous pouvez déployer rapidement des applications analytiques avancées. De par sa nature, TabPy vous permet de bénéficier à la fois des points forts de Tableau et de Python. Vos fonctionnalités de visualisation de données dernier cri sont accompagnées de puissants algorithmes de data science. Avec TabPy, les utilisateurs peuvent ajuster les paramètres de leurs analyses et évaluer l'impact de leurs changements en temps réel, à chaque actualisation du tableau de bord. C'est là l'un des principaux avantages de l'utilisation d'algorithmes Python dans Tableau.
Cette fonctionnalité repose sur un système d'entrée/sortie. Les données sont agrégées en fonction de la visualisation actuelle et transmises à Python avec les paramètres d'ajustement. Les données sont alors traitées, puis les résultats sont renvoyés à Tableau afin de mettre à jour la visualisation. Imaginons que vous disposez d'un tableau de bord qui présente une mesure agrégée. Vous n'êtes pas satisfait du résultat actuel, car vous souhaitez visualiser l'intégralité de l'ensemble de données sous-jacent, ou même afficher plusieurs niveaux d'agrégation à la fois. De plus, vous aimeriez utiliser plusieurs sources de données dans un seul calcul sans pour autant réduire la réactivité de votre tableau de bord.
L'objectif de cet article est de vous aider à mettre en place un système vous permettant de tirer pleinement parti des avantages de TabPy pour les cas d'utilisation suivants :
- Interactions en temps réel : vous souhaitez concevoir une interface utilisateur qui s'actualise en temps réel, dispose d'un temps de traitement limité et met à jour instantanément la visualisation à chaque changement.
- Plusieurs niveaux d'agrégation : vous voulez afficher plusieurs niveaux d'agrégation différents dans les mêmes tableaux de bord Tableau, mais devez effectuer tous vos calculs avec la granularité la plus fine, pour tenir compte de toutes les informations.
- Plusieurs sources de données : les calculs effectués en back-end reposent sur plusieurs sources de données et/ou bases de données.
- Transferts volumineux de données entre Tableau et Python : chaque étape d'optimisation implique d'importants volumes de données, ce qui fait que vous transférez beaucoup de données entre Tableau et le back-end Python.
Une approche novatrice pour l'analytique prescriptive avec TabPy : instructions détaillées
Partons du principe que vous avez déjà installé Python et TabPy. Pour mettre en œuvre TabPy, il vous suffit d'appliquer les trois étapes suivantes :
- Préparation d'une ébauche de tableau de bord Tableau
- Création du back-end de routines de calcul Python
- Conception du front-end Tableau pour exploiter ces calculs
Pour vous guider tout au long de ces trois étapes, j'ai conçu un cas d'utilisation visant à réduire la complexité grâce à l'optimisation d'un portefeuille de produits.
Le cas d'utilisation : réduction de la complexité
Cette procédure d'optimisation concerne un distributeur B2B qui s'est développé principalement à la suite de fusions et d'acquisitions. À cause de cette croissance non organique, il est confronté à une importante complexité. Il évolue sur plusieurs marchés et dispose d'un portefeuille de produits composés d'un millier de références SKU, divisées en plusieurs catégories et sous-catégories. Pour rendre la tâche encore plus ardue, ces SKU sont fabriquées dans plusieurs usines.
La direction de notre entreprise souhaite optimiser ses marges en retirant du marché les SKU les moins rentables. Elle veut cependant continuer à vendre les produits avec des performances passables, afin de conserver une certaine part de marché. En outre, elle tient à ce que ses usines de fabrication dépassent son taux d'utilisation des ressources cible. En effet, une diminution importante renforcerait les coûts fixes de chaque usine.
Pour cet exemple, nous disposons d'une base de données portant sur les SKU. Celle-ci comprend des informations sur les volumes, les coûts et les résultats annuels. Les SKU sont organisées selon deux niveaux hiérarchiques : les catégories et les sous-catégories.
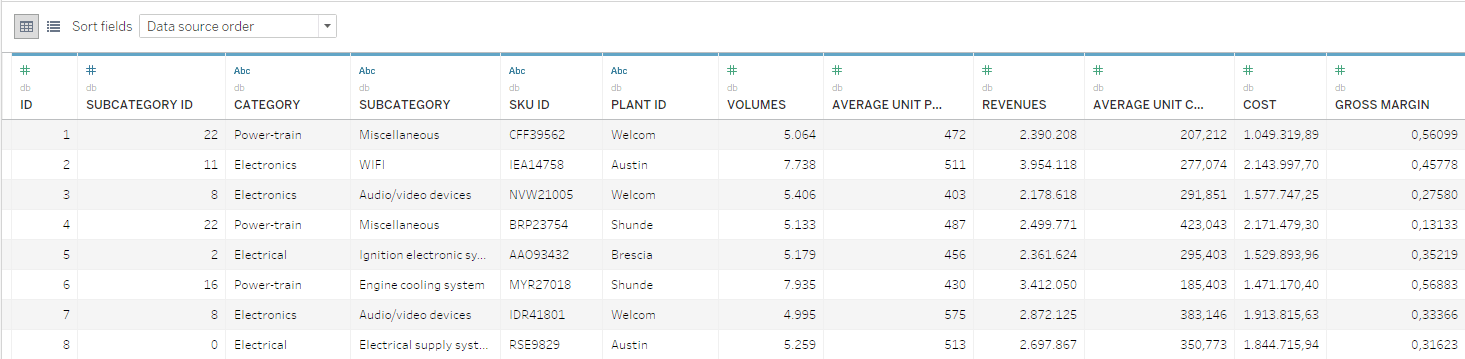
D'un point de vue mathématique, la gestion de l'optimisation produits/portefeuille est relativement simple. Cependant, il convient de prendre en compte toutes les particularités stratégiques et d'inclure un grand nombre de parties prenantes, qui doivent pouvoir accéder aux informations et outils requis pour prendre des décisions éclairées.
La stratégie TabPy détaillée ci-dessous vous permet de répondre à l'ensemble de ces besoins.
1. Préparation d'une ébauche de tableau de bord Tableau
Il est tout d'abord important de s'adapter au problème à résoudre. Ici, un simple algorithme d'optimisation supprimera des SKU en fonction de leur marge brute, calculée au niveau des SKU.
-
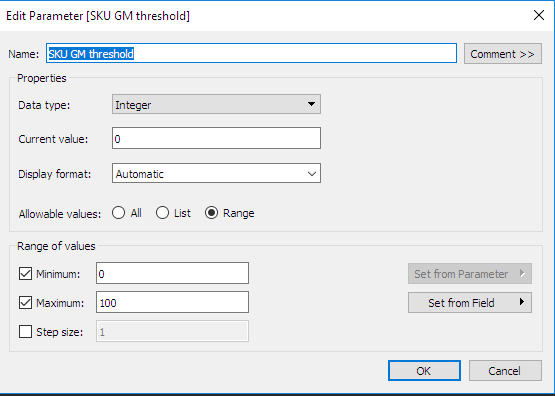
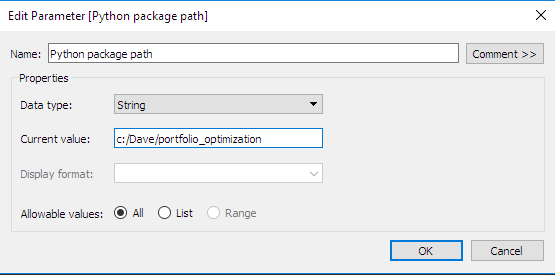
Définissons les paramètres interactifs dans Tableau : vous remarquerez que nous avons défini un deuxième paramètre pratique. Il s'agit du répertoire au sein duquel le package Python contenant les routines d'optimisation sera stocké. Ce type de paramètre simplifie grandement la définition des calculs personnalisés, comme nous le verrons dans la partie suivante.
- Définissons les vues et les niveaux de l'agrégation : nous avons défini deux niveaux d'agrégation, pour les SKU et pour les sous-catégories. Cette étape est cruciale, car elle instaure les signatures des fonctions du back-end Python. Nous devons définir une fonction spécifique pour chaque calcul et chaque niveau d'agrégation. De plus, pour chaque niveau d'agrégation, nous devons créer les paramètres suivants : marges optimisées, recettes optimisées et volumes optimisés.
-
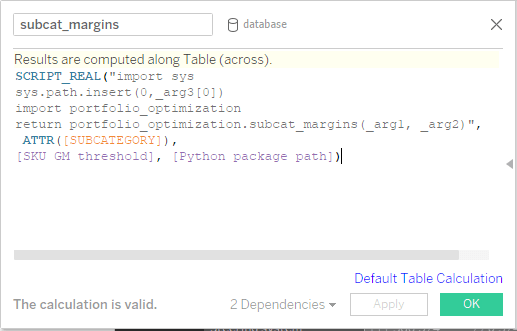
Définissons les hooks (rappels) des calculs dans Tableau : puisque nous avons configuré les paramètres d'entrée, les niveaux d'agrégation et les calculs de sortie requis, nous pouvons à présent définir des calculs personnalisés. Pour des raisons de commodité, toutes les routines d'optimisation ont été structurées dans le package Python portfolio_optimization, au sein duquel nous avons défini les fonctions permettant de renvoyer les quantités sélectionnées pour les niveaux d'agrégation concernés. Vous remarquerez que le paramètre que nous avons préalablement défini, à savoir le chemin du package Python, est transmis à la fonction et utilisé dans le script afin d'indiquer à quel emplacement est stocké le package d'optimisation du portefeuille. De plus, l'indexeur du niveau d'agrégation actuel (p. ex., pour le niveau Sous-catégorie, la sous-catégorie) est toujours transmis au back-end Python afin de veiller à ce que les résultats soient renvoyés dans le bon ordre. Le paramètre d'entrée, « SKU GM threshold » (seuil de marge brute des SKU), est également envoyé.
2. Création du back-end de routines de calcul Python
Le back-end Python est divisé en deux classes de fonction, regroupées selon leur contexte d'exécution. Les fonctions qui sont utilisées une seule fois sont séparées des fonctions aux multiples exécutions. La première classe regroupe par exemple les opérations d'extraction, de transformation et de chargement de base de données. Ces fonctions sont considérées comme des « opérations ponctuelles ». À l'inverse, comme l'ensemble des rappels Tableau, certaines fonctions sont exécutées plusieurs fois :
- Opérations ponctuelles : ici, la base de données est chargée une seule fois, à la première exécution du script. Elle est ensuite transmise à toutes les autres fonctions qui la stockent dans une variable globale. Pour identifier si la base de données a déjà été chargée, Python vérifie auprès de l'espace de noms local s'il existe une copie de la base de données. Sans cette opération, la base de données serait chargée à chaque demande de calcul par Tableau, ce qui nuirait à la vitesse d'exécution.
- Rappels Tableau : chaque hook que nous avons défini doit être exécuté par une fonction. Dans notre cas, nous disposons de calculs distincts pour les recettes, les volumes et les marges. L'indexeur, transmis en tant qu'entrée de la fonction, sert à indexer la fonction groupby Pandas. Cette dernière est ensuite utilisée pour agréger les résultats optimisés. Il est intéressant de souligner que les rappels mettent en place un système de détection des changements de paramètre afin d'accélérer l'exécution. Une nouvelle optimisation est uniquement générée en cas de modification d'un paramètre. Tous les rappels ayant recours à une variable globale peuvent utiliser le résultat de l'optimisation. La détection des changements de paramètre passe par l'utilisation d'une variable persistante. Celle-ci enregistre la valeur du paramètre lors de l'exécution précédente. Cette méthode limite le recours aux opérations chronophages, ce qui améliore les performances d'exécution.
3. Conception du front-end Tableau
Lors des deux premières étapes, nous avons défini le socle requis pour notre cas d'utilisation : niveaux d'agrégation, paramètres à ajuster et colonnes de sortie renvoyées par le back-end de calcul.
Pour faciliter l'analyse de l'optimisation, nous allons créer deux feuilles de calcul distinctes, afin de représenter le portefeuille avant et après le processus d'optimisation. Affichons les deux feuilles de calcul côte à côte.
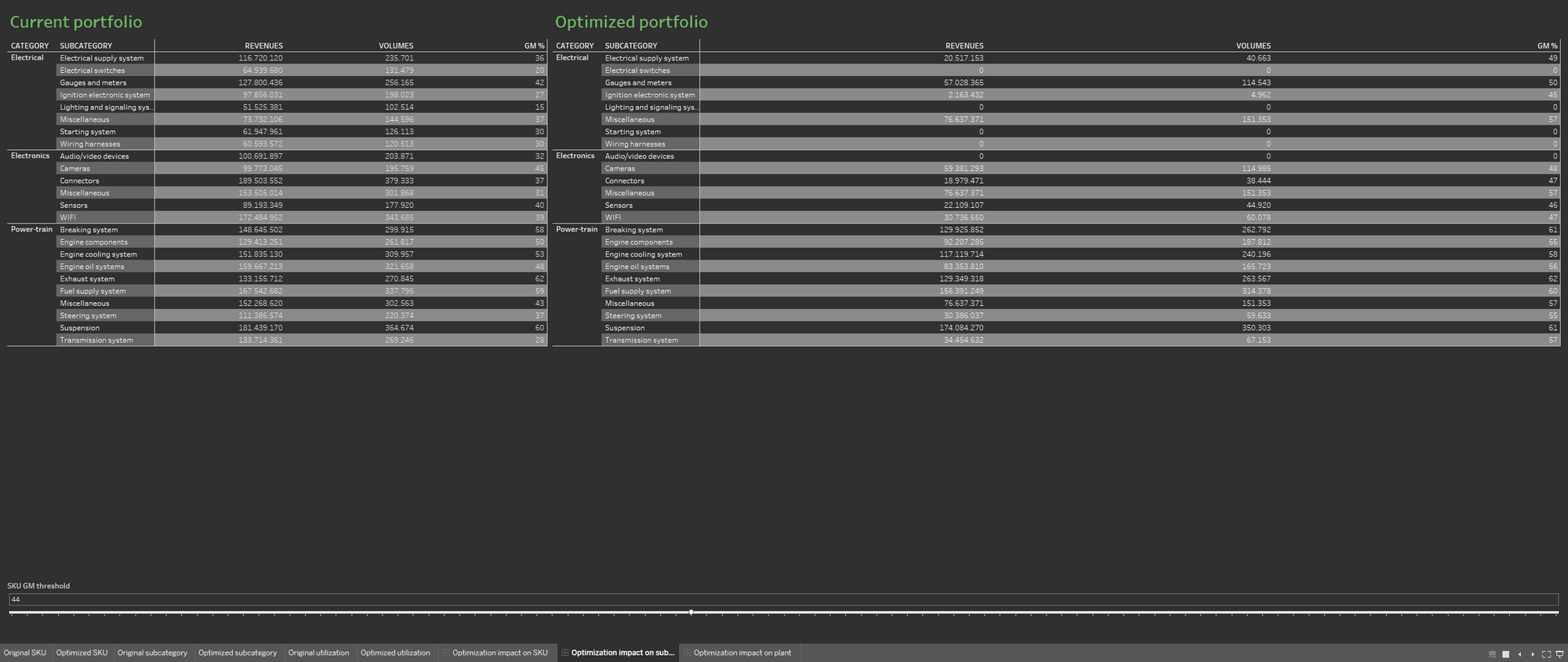
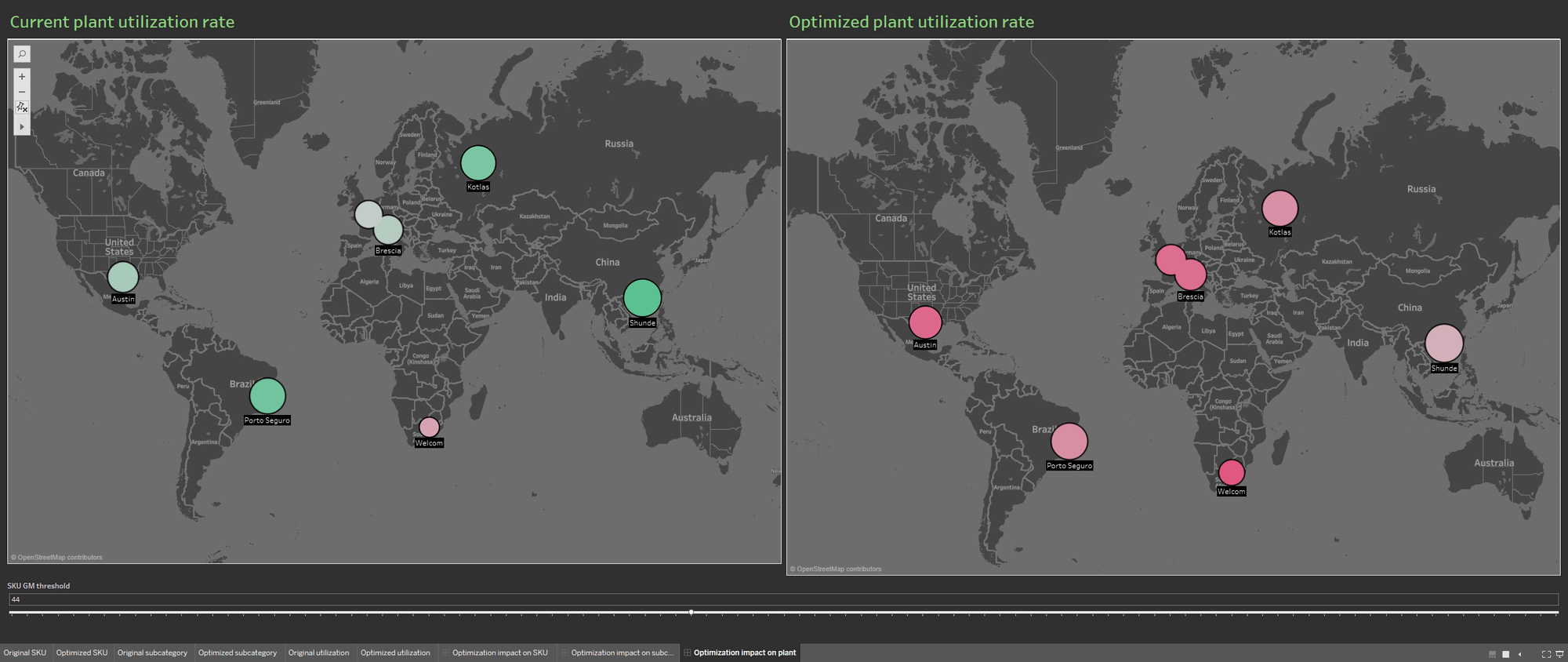
L'apport de plusieurs sources de données enrichit la base de données du portefeuille. Les visualisations comportent ainsi des données sur le taux d'utilisation actuel des usines ainsi que sur le taux résultant de l'optimisation du portefeuille. Avec cette disposition, il est facile de comprendre les conséquences de l'optimisation sur les usines de production.
Autres avantages de TabPy en matière de collaboration
Cette approche innovante génère une valeur métier considérable : les équipes peuvent désormais interagir en temps réel avec les données grâce à de puissantes techniques de data science. Une telle méthode est également bénéfique pour le back-end. De nombreux autres techniques de visualisation de données impliquent la contribution de data scientists, ce qui engendre des coûts importants. Ce n'est pas le cas ici : les data scientists participent uniquement à la préparation de l'ébauche de tableau de bord Tableau et à la création des routines de calcul Python du back-end. Grâce à la facilité d'utilisation de Tableau, la conception du front-end, les tests auprès des utilisateurs finaux et l'entretien du système peuvent être réalisés par des profils bien plus variés.
La conception du front-end implique généralement un processus itératif et chronophage, qui nécessite de nombreux échanges avec les utilisateurs finaux. TabPy innove en offrant aux responsables la possibilité de mettre sur pied une équipe plus diversifiée. À terme, cette stratégie réduit considérablement les coûts. Cette approche garantit également un niveau important de réutilisation du back-end sous-jacent. Un large éventail d'utilisateurs peuvent ainsi créer leurs propres tableaux de bord personnalisés dans Tableau, en fonction d'une situation, d'un contexte et d'un public précis. Cette réutilisation des logiques de calcul et du socle sous-jacent réduit encore plus les coûts totaux associés à la visualisation des données.
Si jamais vous souhaitez explorer plus en détail cet exemple, cliquez ici pour télécharger le tableau de bord Tableau ainsi que le back-end Python. Pour en savoir plus sur cette approche, accédez au référentiel GitHub TabPy officiel ou consultez la conversation de la communauté Tableau à ce sujet.
Articles sur des sujets connexes

VizQL Data Service: Extend Your Data Beyond Visualizations
 mars 19, 2025
mars 19, 2025

VizQL Data Service from Tableau: Use Your Data, Your Way
 août 8, 2024
août 8, 2024

When and How to Use Multi-fact Relationships in Tableau
 août 1, 2024
août 1, 2024
Abonnez-vous à notre blog
Obtenez les dernières nouvelles de Tableau dans votre boîte de réception.