Come associare Tableau e Python per l'analisi prescrittiva con TabPy



Una versione di questo articolo è stata originariamente pubblicata su Medium.
TabPy è un pacchetto di Python che ti permette di eseguire il codice Python in tempo reale e di mostrare i risultati nelle visualizzazioni di Tableau. Così, puoi distribuire velocemente applicazioni di analisi avanzate. L'approccio separato garantito da TabPy consente di utilizzare al meglio due principali funzionalità di visualizzazione dei dati, supportate da potenti algoritmi di data science. Un grande vantaggio di mostrare gli algoritmi di Python in Tableau è che gli utenti possono sintonizzare i parametri e valutarne l'impatto sull'analisi in tempo reale, non appena la dashboard si aggiorna.
Per renderlo possibile, TabPy essenzialmente sfrutta un approccio input/output in cui i dati sono aggregati sulla base della visualizzazione corrente e i parametri di sintonizzazione vengono entrambi trasferiti a Python. I dati vengono elaborati e viene rinviato un output a Tableau per l'aggiornamento della visualizzazione corrente. Supponiamo, però, che per un calcolo ti serva l'intero set di dati sottostanti ma la dashboard mostri una misura aggregata, o che tu voglia mostrare livelli multipli di aggregazione allo stesso momento. Oppure, che tu voglia sfruttare origini dati multiple in un singolo calcolo senza compromettere la capacità di risposta della dashboard.
In questo articolo, ti spiegherò l'approccio utile per sfruttare al meglio il potenziale di TabPy nelle situazioni seguenti:
- Interazione in tempo reale: vuoi avere un'interfaccia utente in tempo reale, che riduca al minimo il tempo di elaborazione e i ritardi tra la modifica di un parametro e l'aggiornamento della visualizzazione.
- Livelli di aggregazione multipli: vuoi mostrare (vari) livelli di aggregazione (diversi) sulle stesse dashboard di Tableau, ma devi eseguire tutti i calcoli utilizzando il livello migliore e più granulare, che contenga tutte le informazioni.
- Varie origini dati: il calcolo di backend si basa su più di una singola origine dati e/o database.
- Dati trasferiti tra Tableau e Python: sono necessari significativi quantitativi di dati per ciascuna fase di ottimizzazione, pertanto devono essere trasferiti molti dati tra Tableau e il backend di Python.
Il nuovo approccio di TabPy per l'analisi prescrittiva: istruzioni dettagliate
Supponendo che sia Python che TabPy siano già installati, per implementare TabPy è necessario eseguire tre passaggi:
- Preparare un modello di dashboard di Tableau
- Creare il backend per le routine dei calcoli in Python
- Progettare il relativo frontend di Tableau
Per spiegarti questi tre passaggi, ho progettato un caso d'uso sulla riduzione della complessità attraverso l'ottimizzazione dell'offerta di prodotti.
Il caso d'uso: riduzione della complessità
Oggetto dell'ottimizzazione è un venditore al dettaglio B2B che ha registrato una crescita principalmente attraverso fusioni e acquisizioni (M&A). Per via di questa crescita inorganica, il venditore deve gestire una grande complessità, poiché opera su vari mercati e ha un'offerta composta da migliaia di SKU (Stock Keeping Unit) divisi in varie categorie e sottocategorie. A complicare ulteriormente la situazione, gli SKU sono prodotti in stabilimenti diversi.
I dirigenti aziendali intendono incrementare i margini rimuovendo gli SKU meno redditizi, pur volendo continuare a vendere quelli con prestazioni più basse per mantenere una determinata quota di mercato. Inoltre, intendono mantenere gli stabilimenti di produzione che operano oltre l'obiettivo di utilizzo degli asset, sapendo che la riduzione eccessiva dell'utilizzo avrebbe effetti negativi sui livelli di costo fissati per ciascuno stabilimento.
I dati disponibili in questo esempio sono costituiti da un database a livello di SKU in cui sono riportati volumi, costi ed entrate annuali. Gli SKU sono organizzati in livelli gerarchici di categoria e sottocategoria.
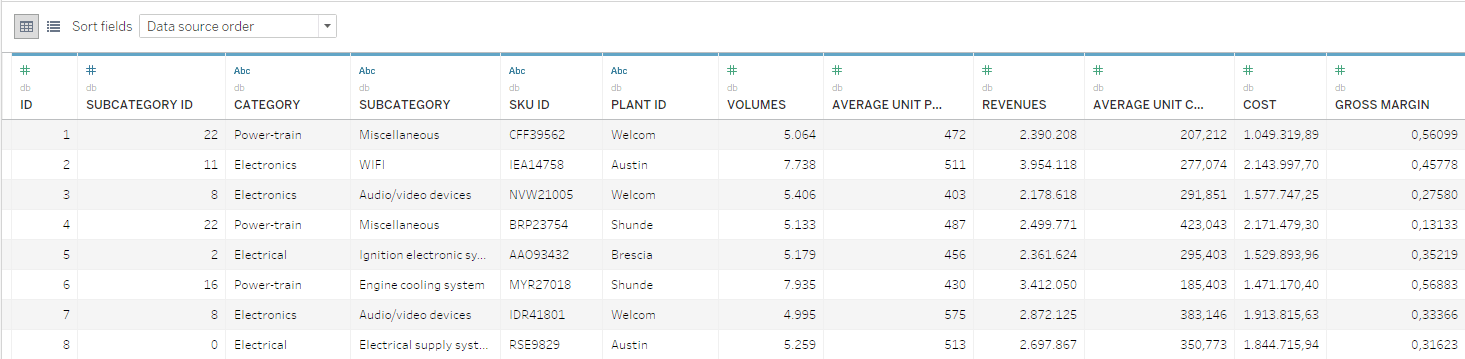
Dal punto di vista matematico, l'attività di gestione dell'ottimizzazione dell'offerta di prodotti è piuttosto semplice. Tuttavia, l'ottimizzazione deve tenere conto anche di tutti gli aspetti strategici e comprendere la partecipazione di un ampio spettro di stakeholder che hanno accesso alle informazioni e agli strumenti necessari per prendere decisioni informate.
L'approccio di TabPy, descritto di seguito, soddisfa tutti questi requisiti.
1. Preparare un modello di dashboard di Tableau
Innanzitutto, è fondamentale identificare il problema da risolvere. In questo esempio, il semplice algoritmo di ottimizzazione rimuoverà gli SKU sulla base del relativo margine lordo, valutato a livello di SKU.
-
Definire i parametri interattivi in Tableau: si noti che per praticità abbiamo definito un secondo parametro. Si tratta della directory in cui sarà archiviato il pacchetto di Python con le routine di ottimizzazione. Come vedremo nella prossima sezione, questo tipo di parametro è molto utile nella definizione dei calcoli personalizzati.
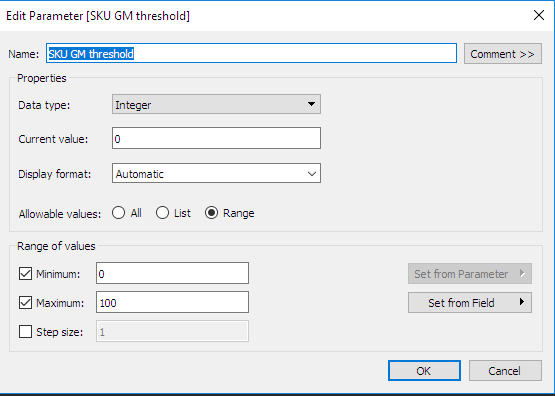
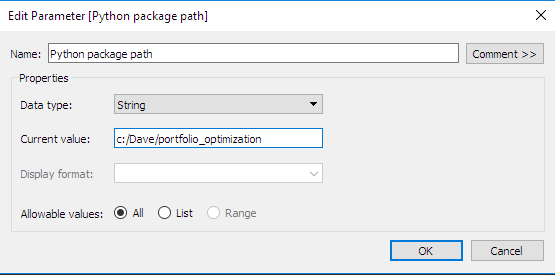
- Definire le viste/livelli di aggregazione: a questo punto, definiamo due livelli di aggregazione, uno a livello di SKU, l'altro a livello di sottocategoria. La definizione dei livelli di aggregazione è fondamentale, poiché definisce le firme delle funzioni del backend di Python. Deve essere definita una specifica funzione per ciascun calcolo e livello di aggregazione. Per ciascun livello di aggregazione, devono essere definiti i seguenti parametri: margini ottimizzati, entrate ottimizzate e volumi ottimizzati.
-
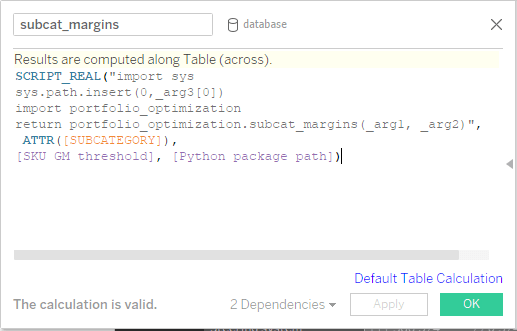
Definire gli hook di calcolo (callback) in Tableau: una volta definiti i parametri di input, i livelli di aggregazione e i calcoli di output necessari, è possibile definire i calcoli personalizzati. Per praticità, tutte le routine di ottimizzazione sono state strutturate in un pacchetto portfolio_optimization di Python, in cui abbiamo definito le funzioni per restituire le quantità selezionate per gli specifici livelli di aggregazione. Vale la pena osservare che il parametro definito precedentemente (il percorso del pacchetto di Python) è trasferito alla funzione e utilizzato nello script per indicare dove è archiviato il pacchetto dell'ottimizzazione dell'offerta. Inoltre, l'indicizzatore del livello di aggregazione corrente (per esempio, per il livello di aggregazione della sottocategoria, o la sottocategoria stessa) è sempre trasferito al backend di Python, per garantire che i risultati saranno restituiti nell'ordine corretto. Anche il parametro di input, la soglia SKU GM, è trasferito.
2. Creare il backend per le routine dei calcoli in Python
Il backend di Python è diviso in due classi di funzioni, raggruppate sulla base del relativo contesto di esecuzione: funzioni eseguite una volta e funzioni ripetute molteplici volte. Per esempio, nella prima classe rientrano estrazioni del database e operazioni di trasformazione e caricamento. Tali funzioni sono chiamate "operazioni singole". Di contro, vi sono le funzioni ripetute molteplici volte, come le callback di Tableau:
- Operazioni singole: in questo esempio, il database è caricato una sola volta, quando si esegue lo script per la prima volta. Il database è quindi reso disponibile per tutte le altre funzioni, essendo archiviato in una variabile globale. Per verificare che il database sia già caricato, Python controlla che nello spazio del nome locale ne esista una copia. In assenza di tale precauzione, il database verrebbe caricato tutte le volte che Tableau richiede un calcolo, determinando un impatto negativo sulla velocità di esecuzione.
- Callback di Tableau: ogni hook precedentemente definito deve avere una funzione di cui si avvale. Nel nostro caso, ciò si ottiene fornendo calcoli separati per entrate, volumi e margini, nonché utilizzando l'indicizzatore trasferito come input della funzione, per indicizzare la funzione groupby di Pandas, poi utilizzata per aggregare i risultati ottimizzati. Vale la pena osservare che, per migliorare la velocità di esecuzione, le callback implementano un rilevatore delle modifiche al parametro. Viene generata una nuova ottimizzazione solo se il parametro è modificato e i relativi risultati saranno disponibili per tutte le callback che sfruttano una variabile globale. Il rilevamento della modifica al parametro è implementato attraverso una variabile permanente utilizzata per archiviarne il valore dell'esecuzione precedente. Questo approccio garantisce l'utilizzo del minimo quantitativo di operazioni onerose, migliorando la velocità di esecuzione.
3. Progettare il frontend di Tableau
Arrivati a questo passaggio, abbiamo definito tutti i profili fondamentali, compresi i livelli di aggregazione, i parametri da sintonizzare e le colonne di output restituite dal backend dei calcoli.
Per rendere l'ottimizzazione più semplice da discutere, definisci due fogli di lavoro separati, che mostrino l'offerta prima e dopo il processo di ottimizzazione. Mostra i due fogli di lavoro affiancati.
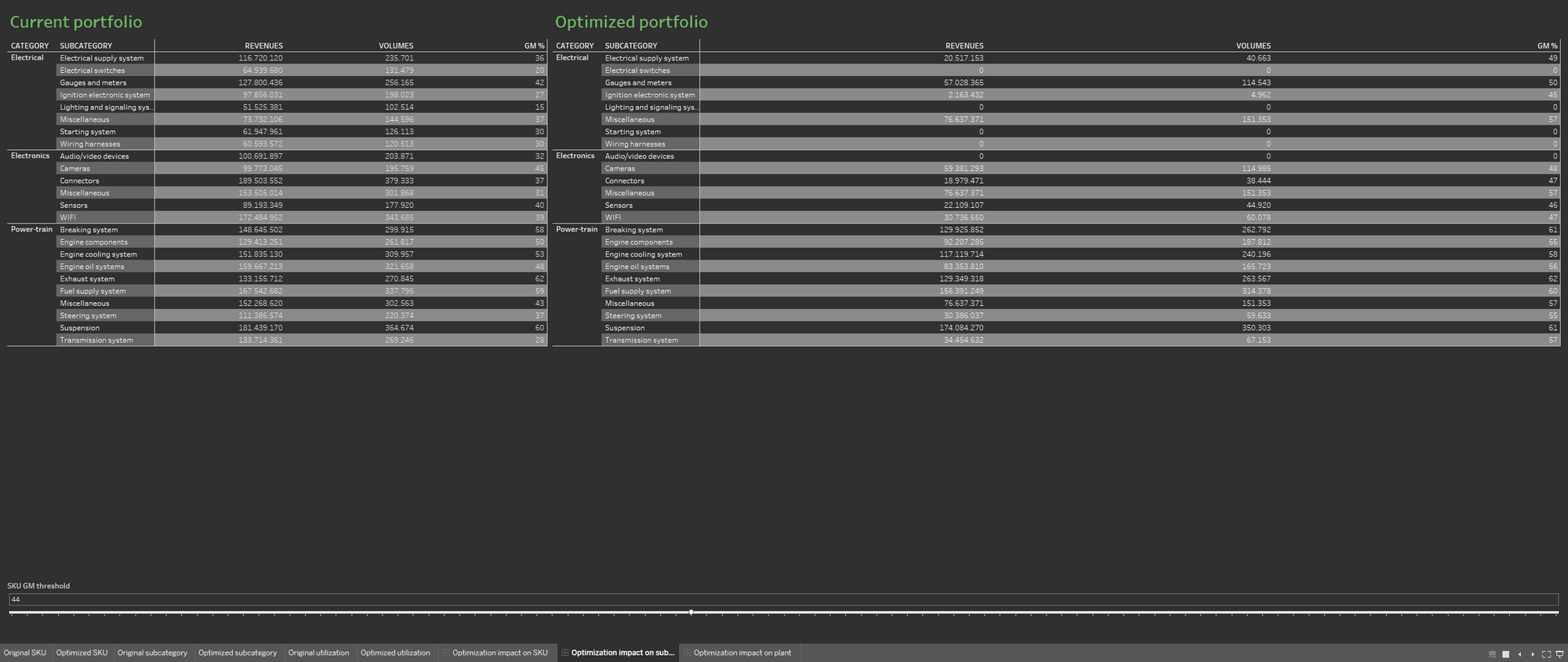
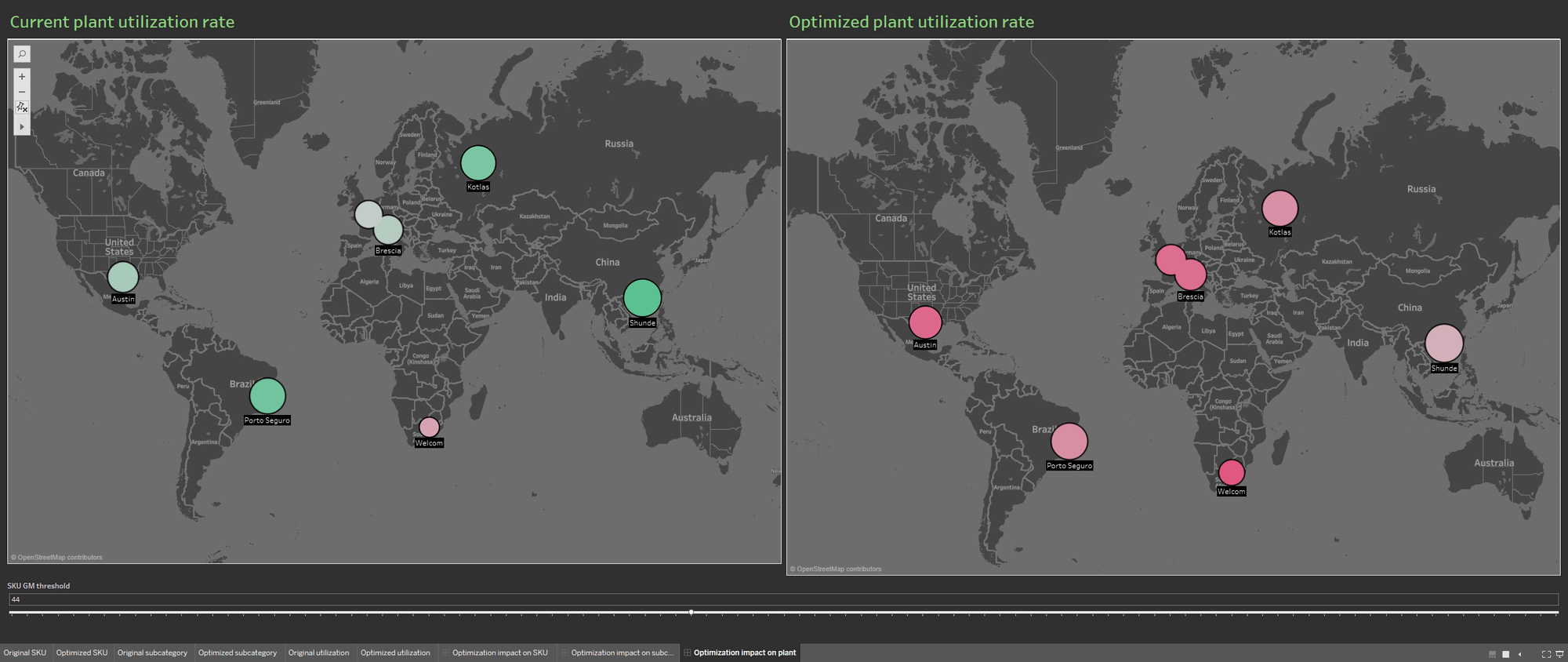
La disponibilità di origini dati multiple arricchisce il database dell'offerta, popolando la visualizzazione con le informazioni sul tasso di utilizzo attuale dello stabilimento e sul tasso derivante dall'offerta ottimizzata. Ancora una volta, le due visualizzazioni delle informazioni vengono mostrate affiancate, per dimostrare al meglio l'impatto dell'ottimizzazione sugli stabilimenti di produzione.
Altri vantaggi dell'utilizzo di TabPy nei team
Oltre al valore significativo per l'azienda creato dalla possibilità per i team di interagire in tempo reale con potenti tecniche di data science, questo nuovo approccio ha anche notevoli vantaggi di backend. Molte altre tecniche di visualizzazione dei dati richiedono la dispendiosa partecipazione di data scientist nell'intero processo. In questo approccio, invece, le risorse di data scientist sono richieste solo per preparare il modello di dashboard di Tableau e creare le routine dei calcoli del backend di Python. La semplicità di utilizzo di Tableau rende possibile una serie molto più ampia di risorse per progettare il frontend, provarlo con gli utenti finali e gestirlo.
La progettazione del frontend è un processo tipicamente lungo e iterativo che necessita di molteplici confronti con gli utenti finali. Dando la possibilità ai manager di variare la composizione dei team durante l'esecuzione del progetto, il nuovo approccio di TabPy può migliorare significativamente l'efficienza in termini di costi. Inoltre, questo approccio garantisce un'elevata possibilità di riutilizzo del backend sottostante, consentendo a un'ampia serie di utenti di sviluppare le proprie dashboard personalizzate in Tableau per adattarle a contesti, destinatari e situazioni specifiche. Il riutilizzo delle logiche di calcolo e dei profili fondamentali sottostanti è un ulteriore modo per migliorare il costo complessivo della visualizzazione dei dati.
Se ti interessa approfondire l'esempio, sia la dashboard di Tableau che il backend di Python sono disponibili qui. Per ulteriori informazioni su questo approccio, consulta il repository ufficiale TabPy su Github o visita questo thread della community di Tableau.
Storie correlate

VizQL Data Service: Extend Your Data Beyond Visualizations
 19 Marzo, 2025
19 Marzo, 2025

VizQL Data Service from Tableau: Use Your Data, Your Way
 8 Agosto, 2024
8 Agosto, 2024

When and How to Use Multi-fact Relationships in Tableau
 1 Agosto, 2024
1 Agosto, 2024
Subscribe to our blog
Ricevi via e-mail gli aggiornamenti di Tableau.