Suelte las riendas de sus fuentes de datos con el servidor de datos



Tableau Server tiene muchas funcionalidades de gobernanza de datos que promueven la exploración, la colaboración y la seguridad. Puede beneficiarse de ellas con el servidor de datos, una eficaz recopilación de funcionalidades que se encuentra en Tableau Server y que suele desaprovecharse. El servidor de datos le permite compartir las fuentes de datos, administrar las extracciones, consolidar el acceso y controlar la seguridad.
Responda estas preguntas para averiguar cómo el servidor de datos puede ayudarlo a ahorrar tiempo e incrementar su productividad:
- ¿Tiene dificultades para administrar y actualizar muchas extracciones grandes y reducir la duplicación al mismo tiempo?
- ¿Tiene un gran número de libros de trabajo que usan la misma fuente de datos? ¿Desea que se actualicen automáticamente cuando cambian los datos?
- ¿Desea ofrecer la administración centralizada de sus metadatos con definiciones estandarizadas para cada campo? Por ejemplo, tener la posibilidad de crear un cálculo una vez y compartirlo con todos.
- ¿Está cansado de tener que implementar y actualizar controladores de bases de datos en la máquina local de cada usuario?
- ¿Desea simplificar el modo en que sus usuarios acceden a los datos almacenados en sus bases y centralizar las credenciales?
- ¿Sus conjuntos de datos son grandes y complejos? ¿Le sería útil que el hardware del servidor ejecutara las consultas?
Si respondió afirmativamente alguna de estas preguntas, llegó el momento de dar rienda suelta al servidor de datos.
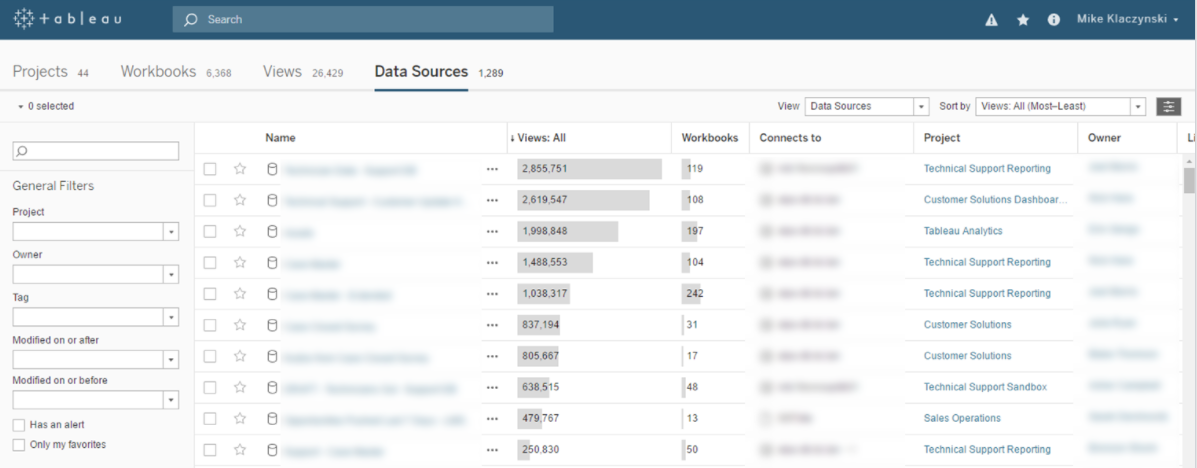
Tableau Server le permite publicar fuentes de datos para compartirlas con otros usuarios y con sus libros de trabajo. Por lo tanto, puede volver a usar extracciones de datos, consolidar conexiones a bases de datos, y compartir cálculos y metadatos de campos. Puede guardar cualquier cambio que haga en la fuente de datos compartida (campos calculados, parámetros, alias o definiciones). Otras personas los verán al instante. Así, los usuarios corrientes pueden complementar el trabajo de los administradores de datos y de bases de datos. Al mismo tiempo, se garantiza que las fuentes certificadas están seguras, se administran de manera centralizada y son estandarizadas.
La publicación es muy sencilla. Basta con hacer clic con el botón secundario del mouse en su fuente de datos, seleccionar “Publicar en servidor…” en Tableau Desktop, escribir las credenciales y especificar los permisos de usuario. Conectarse a una fuente de datos compartida es igual que conectarse a cualquier otra base de datos. Seleccione “Tableau Server” en la lista de conexión, realice la autenticación y seleccione la fuente de datos publicada. Para administrar, modificar o eliminar una conexión de datos, acceda a “Fuentes de datos” en Tableau Server.
Cree una fuente de veracidad única con un repositorio de datos
Tableau Server actúa como repositorio centralizado de los datos y las conexiones de datos. Reduce la proliferación de fuentes duplicadas y contribuye al establecimiento de una fuente de veracidad única. Los libros de trabajo nuevos y existentes que se conectan al servidor de datos se actualizan automáticamente cuando se actualizan las fuentes originales.
La programación de actualizaciones automáticas para las extracciones permite que todos accedan a los conjuntos de datos más recientes. Además, ahorra espacio, ya que evita la necesidad de duplicar las extracciones. Si los usuarios se conectan a una única extracción compartida, se reduce el número de consultas que se hacen a la base de datos original. Por consiguiente, disminuyen las llamadas a la API y los costos de servicio, en particular, las conexiones a servicios que cobran por el acceso a la API, como Salesforce.
Ejecute consultas en el hardware del servidor
Las consultas a grandes extracciones de datos se ejecutan directamente en el hardware del servidor. Como resultado, los tiempos de procesamiento son más cortos y no hay necesidad de transferir la extracción al equipo de cada usuario. Las extracciones con millones de filas y un tamaño de varios gigabytes ya no deben copiarse en cada máquina local. En vez de eso, el hardware dedicado del servidor con múltiples núcleos hace todo el procesamiento. Además, el almacenamiento en una memoria caché compartida acelera significativamente la ejecución de las consultas, ya que los resultados se almacenan de manera local, y los futuros usuarios pueden acceder a ellos de inmediato.
Las credenciales para las conexiones a bases de datos en tiempo real pueden incrustarse en las fuentes publicadas. De ese modo, el servidor de datos actúa como proxy sin solicitar la autenticación de cada usuario en la base de datos original.
Consolide los controladores de bases de datos
Instale un solo conjunto de controladores de bases de datos en el servidor para que se ocupe de todas las conexiones a bases de todos los usuarios. Así, se evita la necesidad de que cada usuario instale y actualice los controladores en su máquina local. En consecuencia, las organizaciones con grandes implementaciones de escritorio ahorran tiempo.
Preserve los valiosos metadatos
Las fuentes de datos publicadas no son solo conexiones a bases de datos. Contienen metadatos y actúan como una capa semántica cuidadosamente seleccionada para todos los usuarios. Oculte los campos sin importancia, organice los campos en carpetas y cree cálculos, agregaciones, parámetros, conjuntos, grupos y uniones predefinidas entre tablas. Así se crea la única capa semántica que comparten todos los usuarios de sus libros de trabajo.
Por lo tanto, se propicia el autoservicio, ya que los analistas vuelven a usar modelos confiables mientras los optimizan con sus propios cálculos y descripciones. La fuente de datos publicada protege a los usuarios de la renovación de la capa física. Si se requiere algún cambio en la estructura subyacente de los datos, los administradores de la base de datos pueden hacer la modificación y aplicarla en todos los libros de trabajo que usan esa fuente.
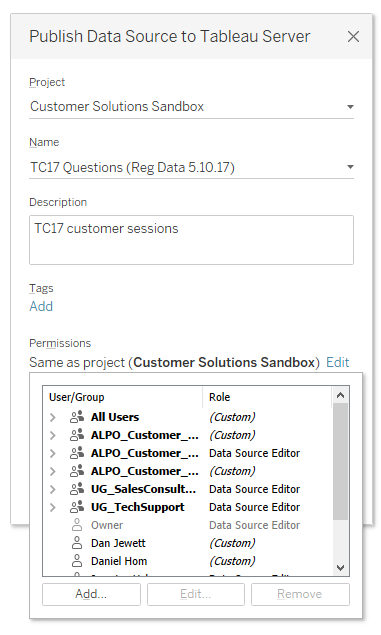
Garantice la integridad de los datos y configure permisos
Además de mantener los metadatos de una fuente, los administradores pueden crear restricciones basadas en los permisos y en los filtros para el nivel de usuario. Así, serán capaces de controlar mejor la visibilidad que tiene cada usuario de las distintas porciones de datos. Por consiguiente, se puede almacenar una sola extracción o conexión de datos, sin necesidad de crear conjuntos de datos individuales para cada usuario.
Se pueden otorgar permisos a un conjunto limitado de usuarios para que editen los metadatos de la fuente. Ellos serán los responsables de garantizar la integridad de los datos y de administrarlos. De este modo, los usuarios corporativos pueden confiar en la información que obtienen a partir de los datos. No necesitan comprender la estructura de la base de datos subyacente, conocer las definiciones apropiadas de los campos ni cuestionar la integridad de los datos.
Más información
El servidor de datos puede ayudar a automatizar y estandarizar las fuentes de datos de su organización. Para ello actúa como proxy veloz y seguro y como un repositorio de extracciones. Obtenga más información en nuestro video de capacitación sobre el servidor de datos.
Para profundizar aún más, consulte estos temas en la Ayuda de Tableau:
Historias relacionadas

How EMD Serono is improving patient care with personalized, AI-powered insights from Tableau
 30 Septiembre, 2024
30 Septiembre, 2024
Embedded Analytics: Should you build or buy?
 7 Junio, 2022
7 Junio, 2022

IT’s role in building a Data Culture: Analytics agility, proficiency, and community
 6 Diciembre, 2021
6 Diciembre, 2021
Suscribirse a nuestro blog
Obtenga las últimas actualizaciones de Tableau en su bandeja de entrada.