Le serveur de données libère le potentiel de vos sources de données



Tableau Server offre de nombreuses fonctionnalités de gouvernance des données conçues pour encourager l'exploration et la collaboration et promouvoir la sécurité. Vous pouvez en tirer parti grâce au serveur de données, un ensemble de fonctionnalités puissantes, mais souvent sous-utilisées. C'est lui qui permet de partager des sources de données, de gérer les extraits, de consolider l'accès et de contrôler la sécurité.
Répondez aux questions suivantes pour découvrir comment le serveur de données peut vous aider à gagner du temps et à accroître la productivité.
- Avez-vous du mal à gérer et mettre à jour de nombreux extraits volumineux tout en réduisant la duplication ?
- Est-ce que beaucoup de classeurs utilisent la même source de données, et souhaitez-vous les mettre à jour automatiquement lorsque les données changent ?
- Souhaitez-vous fournir la gestion centralisée de vos métadonnées avec des définitions normalisées pour chaque champ (en permettant par exemple de créer un calcul une seule fois et de le partager ensuite avec tout le monde) ?
- En avez-vous assez de déployer et de mettre à jour des pilotes de base de données sur l'ordinateur de chaque utilisateur ?
- Souhaitez-vous simplifier l'accès de vos utilisateurs aux données stockées dans vos bases de données et centraliser les informations d'identification ?
- Vos ensembles de données sont-ils complexes et volumineux ? L'exécution des requêtes par le serveur serait-elle avantageuse pour vous ?
Si vous avez répondu « oui » à l'une de ces questions, l'heure est venue de libérer toute la puissance du serveur de données.
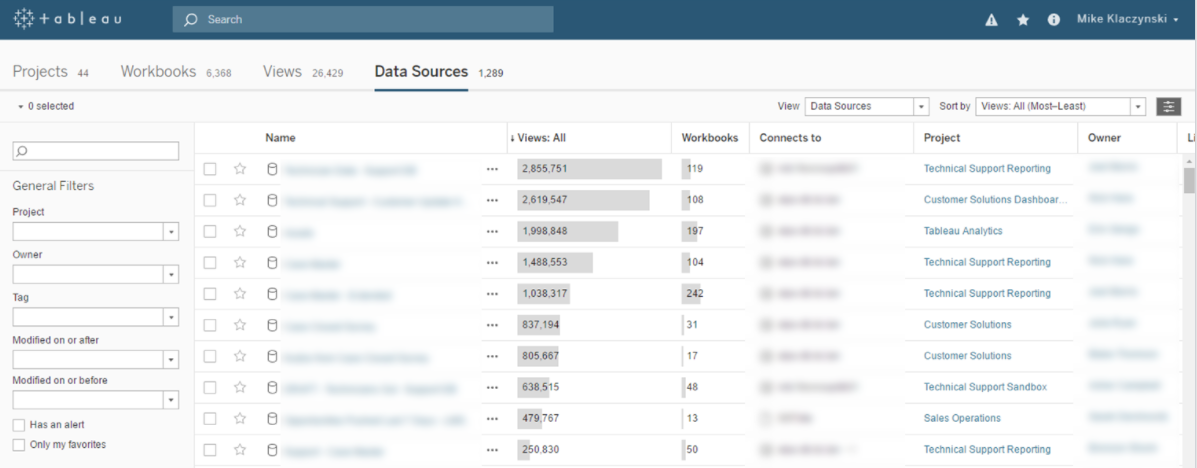
Tableau Server vous permet de publier des sources de données afin que d'autres utilisateurs puissent les exploiter et les ajouter à leurs classeurs. Vous pouvez ainsi réutiliser des extraits de données, consolider des connexions aux bases de données et partager des calculs ainsi que des métadonnées au niveau des champs. Toutes les modifications que vous apportez à la source de données partagée, qu'il s'agisse de champs calculés, de paramètres, d'alias ou de définitions, peuvent être enregistrées et accessibles immédiatement. Ainsi, les utilisateurs ordinaires tirent parti du travail des responsables des données et des administrateurs de base de données. Par ailleurs, cela garantit que les sources de données validées sont fiables, normalisées et gérées de manière centralisée.
Pour publier votre source de données, cliquez simplement dessus avec le bouton droit, sélectionnez « Publier sur le serveur » dans Tableau Desktop, saisissez vos informations d'identification et spécifiez les autorisations utilisateur. Pour vous connecter à une source de données partagée, procédez de la même façon que pour les autres : choisissez « Tableau Server » dans la liste de connexions, authentifiez-vous et sélectionnez la source de données publiée. Les connexions aux données peuvent être administrées, modifiées ou supprimées dans la vue « Sources de données » de Tableau Server.
Une seule et unique source d'informations
Tableau Server fait office de référentiel centralisé pour les données et les connexions, ce qui réduit la prolifération de sources de données en double et permet d'obtenir une seule et unique source d'informations. Les classeurs, nouveaux ou existants, qui se connectent au serveur de données s'actualisent automatiquement lorsque les sources de données d'origine sont mises à jour.
La planification de l'actualisation automatique des extraits permet à tout un chacun de disposer des ensembles de données les plus récents et de libérer de l'espace, puisqu'il n'est plus nécessaire d'avoir des extraits en double. Faire en sorte que les utilisateurs se connectent à un seul extrait partagé permet de réduire le nombre de requêtes sur la base de données d'origine. Résultat : les coûts des services et le nombre d'appels d'API diminuent, en particulier lors de la connexion à des services qui facturent l'accès à l'API, tels que Salesforce.
Exécution des requêtes sur le matériel serveur
Les requêtes sur des extraits de données volumineux sont directement exécutées par le matériel du serveur, ce qui entraîne des temps de traitement plus courts et élimine la nécessité de transférer l'extrait sur l'ordinateur de chaque utilisateur. Rendez-vous compte : ce sont des millions de lignes, soit plusieurs gigaoctets, qui n'ont plus besoin d'être copiées en local. Au lieu de cela, le traitement est assuré intégralement par le processeur multicœur du serveur. En outre, la mise en cache partagée accélère considérablement l'exécution des requêtes. En effet, les résultats sont mis en cache localement, et les futurs utilisateurs peuvent y accéder instantanément.
Les informations d'identification pour les connexions en direct aux bases de données peuvent être intégrées aux sources de données publiées. Le serveur de données fait alors office de proxy et les utilisateurs n'ont pas besoin de s'authentifier auprès de la base de données d'origine.
Consolidez vos pilotes de base de données
Installez un seul ensemble de pilotes de base de données sur le serveur afin de gérer toutes les connexions aux bases de données pour tous les utilisateurs. En procédant de la sorte, ces derniers n'auront plus à installer et mettre à jour les pilotes sur leur machine locale. Cela offre un gain de temps non négligeable pour les structures qui déploient beaucoup d'ordinateurs de bureau.
Préservez vos précieuses métadonnées
Les sources de données publiées sont bien plus que de simples connexions à des bases de données. Elles contiennent des métadonnées et offrent une couche sémantique toute prête. Masquez les champs sans importance, organisez les champs dans des dossiers, créez des calculs, des agrégations, des paramètres, des ensembles, des groupes et des jointures prédéfinies entre les tables de manière à créer une seule couche sémantique pour tous les utilisateurs et leurs classeurs.
Procéder de la sorte encourage l'utilisation en libre service, car les analystes réutilisent des modèles fiables tout en les améliorant avec leurs propres calculs et descriptions. Avec une source de données publiée, les utilisateurs n'ont plus à s'occuper de la couche physique : si des modifications sont apportées à la structure sous-jacente des données, l'administrateur de base de données peut les effectuer. Elles se propageront ensuite automatiquement dans tous les classeurs utilisant cette source de données.
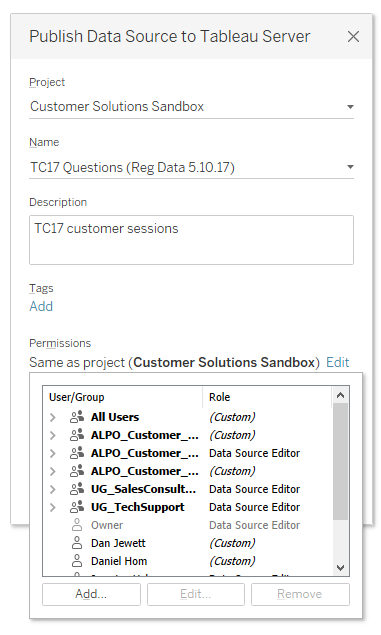
Intégrité des données garantie, définition des autorisations
En plus de la gestion des métadonnées d'une source de données, les administrateurs peuvent créer des restrictions en fonction des autorisations et des filtres du niveau utilisateur pour mieux contrôler ce que peut voir chaque utilisateur. Cela consiste à stocker une seule connexion de données ou un seul extrait. Il n'est pas nécessaire de créer des ensembles de données uniques pour chaque utilisateur.
Les autorisations pour la modification des métadonnées de la source de données peuvent être limitées à quelques utilisateurs spécifiques chargés de l'administration et de l'intégrité des données. Les utilisateurs métier peuvent ainsi se fier aux informations exploitables qu'ils trouvent dans les données sans avoir à comprendre la structure sous-jacente de la base de données ou les définitions de champ appropriées, ni à se préoccuper l'intégrité des données.
En savoir plus
Découvrez dans notre vidéo de formation comment le serveur de données peut vous aider à automatiser et normaliser les sources de données de votre entreprise en faisant office de proxy rapide et sécurisé et de référentiel d'extraits.
Pour en savoir plus, consultez les rubriques suivantes dans l'aide de Tableau :
Articles sur des sujets connexes

How EMD Serono is improving patient care with personalized, AI-powered insights from Tableau
 septembre 30, 2024
septembre 30, 2024
Embedded Analytics: Should you build or buy?
 juin 7, 2022
juin 7, 2022

IT’s role in building a Data Culture: Analytics agility, proficiency, and community
 décembre 6, 2021
décembre 6, 2021
Abonnez-vous à notre blog
Obtenez les dernières nouvelles de Tableau dans votre boîte de réception.