Tableau Research: Ready paper one
Tableau Research is the industrial research team at Tableau and they've begun a technical note system to provide context around their research exploration. Learn about how the Research team applied two techniques to approach the complex problem of parsing dates and their various formats. One technique focused on pattern recognition while the other focused on natural language grammar rules.






Tableau Research is the industrial research team here at Tableau. Our job is to explore the road ahead for the rest of the development team and make recommendations for future work.
When Tableau released the DATEPARSE feature to parse dates, we found that 15% of the user-authored date format strings that were extracted from Tableau Public were invalid. The research team decided to focus on this problem given that date formats are complex and occur in a myriad of forms. The challenge is to develop algorithms for detecting such patterns and further determine how accurate the algorithms are. Tableau Research consists of a diverse set of research scientists focused on the same goal of helping people see and understand data, yet from different perspectives ranging from color theory, storytelling, statistics, HCI to natural language processing. The work on DATEPARSE was reflective of that diversity by approaching the same problem of better parsing of dates, yet from different points of view: one focusing on pattern recognition while the other using natural language grammar rules. These complementary approaches helped cross-validate the other algorithm to assess its precision and accuracy.
Often research exploration is written up as academic papers, but not every paper that the research group produces ends up being published. This can be for a number of reasons, but it isn't usually because the work is uninteresting. To deal with this problem, we have started a technical note system on the Tableau Research website and are happy to announce that the first note has been published: "Does Anybody Really Know What Time It Is: Automating the Extraction of Date Scalars" by Richard Wesley, Vidya Setlur, and Dan Cory. The work described was shipped as Automatic DATEPARSE for Tableau 10.2 in 2017. We will describe this work informally here, but please read the paper for more details.
Error rate
One of the most common data preparation operations that users perform in Tableau is converting strings to dates. For many years, the only tool users had was various string functions, which lead to complex error-prone formulas. To help users with this problem, we introduced the DATEPARSE function to our calculation language. This used a single formatting syntax for all databases and enabled users to write simple expressions to convert strings to dates.
This was great in theory, but after a few months in the wild, we decided to check on how it was working for our users. We found that when we looked at their attempts on Tableau Public, users had a 15% syntax error rate. Even that figure assumes that the valid syntaxes are actually correct, which is hardly guaranteed.
The trouble is that users rarely need this functionality and are essentially relearning a complex mini-language every time they need to use it for a small problem. And it’s not just casual users either. We implemented our syntax and do a lot of research on time analytics, yet we had to relearn a lot of it every time we needed it! Why should our users have to be masters of a system that we ourselves are far from automatic at deploying?
A tale of two techniques
| ICU Format | Example |
|---|---|
| EEE MMM dd HH:mm:ss zzz yyyy | Fri Apr 01 02:09:27 EDT 2011 |
| [dd/MMM/yyyy:HH:mm:ss | [10/Aug/2014:09:30:40 |
| dd-MMM-yy hh.mm.ss.SSSSS a | 01-OCT-13 01.09.00.000000 PM |
| MM ''yyyy | 01 '2013 |
| MM/dd/yyyy - HH:mm | 04/09/2014 - 23:47 |
This was too large a collection of formats to handle with a small list. Clearly, we needed an automated system for generating the formats for the user. As it happened, we developed two different algorithms—minimum entropy and natural language—for generating format strings. We then applied these two algorithms to the corpus of date string columns extracted from Tableau Public; we used them to cross-check each other and found a high level of agreement. This agreement was interesting because the amount of data was quite large, yet we were not applying machine learning (ML) techniques.
Technique 1: Minimum Description Length (MDL)
We had been looking at the Potter's Wheel data cleaning paper, which includes a structure extraction algorithm called Minimum Description Length (MDL) that tries to express the layout of a record by representing it as a sequence of domains and choosing the shortest (most compressed) representation. We wondered if we could adapt this algorithm to use temporal domains corresponding to the ICU field symbols.
The big problem is that temporal domains are ambiguous. For example, how do you tell the difference between 12-hour fields and months? Because the system generates and ranks all valid patterns, you will get both of them, so we needed some way of choosing between the generated matches. (The ranking is by compression, not semantics.) Moreover, because the structure generation is exponential in the number of domains and matches, it is vital to prune early and prune often.
Part of our solution was to come up with a more powerful set of pruning APIs for the domains. For example, the original domains from the paper only pruned immediately previous domains, but we extended this to look backwards to the start of the pattern so that domains can require that they be unique (e.g., only one month). Another extension was requiring context for some domains (e.g., a meridian domain can only occur after a 12-hour domain). These are fairly natural extensions to the original domain API, but they were essential for reducing the search space.
The other big change was a set of post-generation pruning rules that understood the usual semantics of dates. Most notably, it removed domains with place-value gaps (e.g., hours and seconds with no minutes) as these are too underspecified to be parsed correctly. And as usual, two-digit years required some special handling.
Technique 2: Natural Language (NL)
Vidya Setlur, our natural language expert, became interested in the problem and developed an alternative approach using context-free grammar. She had been interested in exploring probabilistic context-free grammars (PCFGs) to explore how data could be transformed into known, structural formats.
A natural language (NL) grammar approach allows for greater expressibility and flexibility in defining rules for parsing various date formats. The grammar can easily be extended with new production rules and assigned a probabilistic weight depending on the underlying semantics of the data context.
One common issue with date formats is ambiguity in the parse. For example, take the date value "5/10/2016". This value could be interpreted as "May 10, 2016" or "October 5, 2016." Determining if the data column that the value is present in is a middle-endian or little-endian format, which is ambiguous. So, in this case, the grammar rule for parsing either of these endian formats is equally probable, with a weight of 0.5. However, if there are other values in the data column such as "26/04/2012," based on the semantics of calendar months and days, this value can only be of a little-endian format, namely "April 26, 2012." The system can then adjust the probability weights of the little-endian and middle-endian production rules accordingly, setting them to say, 0.8 and 0.2 respectively.
Vidya implemented a complementary approach to our own DATEPARSE work to help cross-validate the precision of the approaches in recognizing the most common date formats that are present in the data.
Duking it out
We extracted the testing corpus from Tableau Public workbooks and found about 62,000 non-date columns that appeared from the column names to contain dates. This included columns that contained integers as they may have been incorrectly parsed by Excel. Some of these integer columns were clearly not dates, so we removed columns where the values did not fit a few ranges. We then sampled each column by throwing out NULLs and randomly choosing 32 values. Finally, we split the data into training and test data and ran both algorithms over the data to compare the output:
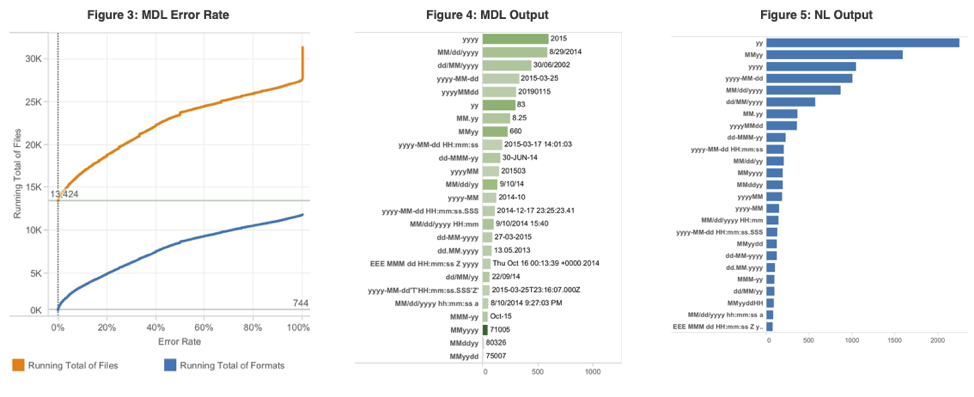
There are some differences between the two algorithms, but they were mostly for ambiguous data and the agreement rate was about 98%. This gave us a lot of confidence in the results, showing the value of cross-checking algorithms.
Fast enough
The Minimal Entropy approach was written in C++ and was the one we eventually shipped, so we did some performance testing as well. The results were an analysis rate of about 2.3 ms per value and a validation rate of about 1.7 µs per value on a 24-core Dell T7610. Given a sample size of 32, this is well below what most users would even notice—and of course it has the benefit of being correct without them needing to learn the syntax!
A common publishing problem is not being able to find a relevant venue for interesting work, and this paper is an example of the problem. Through our new Tableau Tech Notes, we will be able to get word out about the work we do behind the features more quickly and easily.
Read the full Tech Note about the Automatic DATEPARSE feature on the Tableau Research page here.
Autres sujets pertinents

Unlocking Actionable Insights with Jupybara: A Multi-Agent AI Assistant for Data Analysis and Storytelling
 23 Mai, 2025
23 Mai, 2025

AI-Assisted Authoring of Text and Charts for Data-Driven Communication
 4 avril, 2025
4 avril, 2025

Beyond the Default: Customizing Automated Data Insights with GROOT
24 octobre, 2024
Abonnez-vous à notre blog
Recevez toute l'actualité de Tableau.