Porting Tableau Server to Linux, Part 1
In this first post, we'll cover the timeline and the nitty gritty details of getting the code to run on Linux; the second discusses some of the design choices we made along the way.




When Tableau began in 2003, it was strictly a Microsoft Windows product, as was Tableau Server, which we first shipped in 2008. While many customers happily ran Server on Windows, there was growing interest in running it on Linux servers, as well. This became more important as cloud computing picked up.
In one of my first team meetings, I was asked how long I thought it would take me to port Tableau Server to Linux. I considered my prior experience porting code at other jobs–something I’d done with relative ease. And since I was the new guy and wanted to demonstrate my ambition to my new colleagues, I famously predicted that the port would take me three days. That was in 2008; we successfully completed the port in early 2018. I was only off by ten years!
The journey from inception to completion was a long one. Porting Tableau Server to Linux began with a false start in 2008, gained some traction with one massive effort by almost the entire Dev team to port the code base to Mac, and finally reached success with a concerted effort by a much smaller team. This blog post chronicles the journey, details the challenges faced along the way, and tells the story of how the Linux version of Tableau Server came into existence.
Because the scope of the project is large, we have split our story into two posts. The first post covers timeline and the nitty gritty of getting the code to run on Linux; the second discusses some of the design choices we made along the way.
First Tableau Server Linux porting effort
For six months, in fits and starts, from 2008 to 2009, I took a stab at compiling our C++ code base with GNU’s g++ compiler. I could get all of the code to compile but not to link. It wasn't a serious porting effort–more of an experiment to see how much effort it would take to port. The answer turned out to be A LOT, as our code base had Windows APIs deeply woven into it.
While the port itself wasn’t successful, this effort did yield one unexpected benefit: the code base was improved by compiling it with a different compiler. I fixed numerous instances of a particular suppressed compiler warning on Windows because g++ didn’t have a convenient way to suppress all the ways that warnings could be triggered. I then un-suppressed the warning on Windows and the code base was better for it. Compiling against g++ also revealed some amusing bits of code that MSVC happily accepted.
g++ rejects this code:
class Foo {
Foo::method1() ...
Foo::method2() ...
};
because Foo:: is included in the method declaration. The above is not the standard way to declare a class but MSVC is very lenient. g++ also rejects this bit of preprocessor code:
#endif FOO_H
While g++ insists you say:
#endif // FOO_H
Another interesting finding was that the MSVC documentation suggests it will also reject the above code, but it does not. MSVC also accepts unterminated multi-line C-style comments inside of terminated multi-line C-style comments, no newlines at the end of files, file static functions that are prototyped in header files and included in multiple compilation units, and duplicate typedefs repeated multiple times in the same class/header.
By far the most common type of g++ compile error was letter case inconsistencies (you will hear a lot more about these later). Windows is basically case-insensitive to filenames; Linux is not. The most common occurrence of this was a mismatch between the name of the file on the filesystem and how it was referenced in the code: where the file was named foo.h and the code said #include "Foo.h". This type of error occurred hundreds of times. I fixed all these irregularities, but since there was no automated test build preventing more of these errors from occurring, I found more every time I synced new code from my coworkers.
Even though this first port attempt didn't lead to a Linux version of Server, the code base was still improved (temporarily)! This porting effort was abandoned when it was clear how much effort it would take versus the business priorities of other tasks.
Linux creeps in: porting the data engine to Linux
During a hackathon at the end of 2010, I ported the Tableau Data Engine (recently superseded by the Hyper Data Engine) to Linux with another developer. We spent a month doing it, and this port was much more fruitful than my first attempt. The Data Engine was carefully architected to have very few Windows API dependencies, and those that it had were abstracted away in leaf classes that could easily be swapped out for other implementations. The code mostly made use of C++ standard language features instead of Windows-specific ones so mostly it "just worked." At the end of the month, the Data Engine was running on Linux with very few test failures. The result of this port lived on beyond the hackathon. The remaining failures and inconsistencies were fixed with minimal effort, and the Linux version of the Data Engine was maintained and used internally throughout the organization.
The great Mac port
The biggest step in successfully bringing Tableau Server to Linux was to remove Windows-specific APIs from our entire C++ codebase. This happened when a significant portion of the Dev team ported Tableau Desktop to the Mac in a concerted effort from early 2013 to mid-2014, culminating with the release of Tableau Desktop 8.2 for Mac in June 2014.
Everything had to be abstracted and refactored. Tableau chose Qt for its support of cross-platform libraries. Instead of Windows CString for strings, an internal TString class was created that was built upon Qt's QString classes. All of Tableau’s rendering was rewritten away from Windows GDIPlus in favor of Qt rendering classes. Windows WinINET networking code was retargeted to Qt networking classes. Tableau hired contractors who painstakingly ported all dialogs from a Windows native to Qt's cross-platform .ui files.
In addition to the actual code, Tableau build systems and processes had to expand to support multiple platforms. The build definition was ported from Visual Studio solution files to CMake/Ninja. A Mac build grid was created, and we switched to using a Continuous Integration (CI) system that allowed all check-ins to be simultaneously tested on both platforms.
A Linux hackathon generates excitement
The Mac port paved the way for Tableau Server on Linux, just as enterprise customers and Tableau internal groups were demanding a Linux version in a new world of cloud computing. Coincidentally, in the spring of 2015, three developers worked for a number of weeks on a hackathon attempting to get Tableau Desktop running on Linux. Those three intrepid developers were able to build and run Tableau Desktop on Linux with hackathon quality. The fruits of their labor were not production ready, but the work definitely provided proof of concept, and it was a really cool demo that got people excited.
Porting Tableau Server to Linux
In the summer of 2015, the port of Tableau Server to Linux began in earnest. We couldn't enable building the source code in our Linux build farm until the code could be built and linked successfully. This meant that for six months the porting progress was innocently hampered by the entire dev team who constantly checked in source code changes, and in so doing, unwittingly added more Linux compile errors. It was a race. The number of porting developers, first me and then later another developer, was no match for the number of other developers (hundreds) who were busy building new features and had no idea they were destabilizing the Linux build. Even though the code had been ported to OSX, and even though our OSX build farm was verifying the OSX build, many Linux-only build and link errors were checked in on a daily basis. Our OSX file systems were also case insensitive, so file path case errors were by far the single biggest causes of build failures (again,more on this later). Also, the Tableau Server C++ code included different code than Tableau Desktop code, so that new code had to be freshly ported from Windows. Some interesting tidbits:
- We had assumed in many places that
sizeof(wchar_t)is 2 bytes, which is true on Windows but not on Linux where it is 4 bytes. Because MSVC strings, Tableau's string class and Java's internal string representation are all two byte characters, many places in the code always assumed two bytes per wide character. On Linux, this assumption was wrong and could produce both compile and runtime errors. - STL containers could not be defined with
constobjects (a limitation of g++ at the time) - g++ does not allow a single line comment to end with a line continuation character (backslash). Enabled with
-Wcomment - MSVC will let you assert on the address of a stack allocated object or test the address of a stack allocated object against nullptr. g++ rightfully says you're crazy.
- MSVC will let you have a redundant typedef:
typedef Foo Foo; g++ not so much
Each day, there was a race to sync changes and fix them to keep the code building and linking locally. But we couldn't keep up. New errors of all kinds were getting checked in faster. We needed to have the entire dev team stop checking in code so that we could get a stable Linux build. And we needed to enable the Linux build farm so that future build breaks would be automatically caught. Luckily for our team of two, Tableau Conference 2015 arrived. Most of the Dev team departed for the week, and we had our chance to stay behind and enable the Linux build. Phew!
At this time, our build farm was a block of physical Linux machines that was used to build the Linux Data Engine and Extract SDK source code. Until we could expand our build farm to handle building the entire code base on Linux with each check-in, we made do with hourly builds.
File case sensitivity in source control
In the initial port experiment in 2008, the source code size was just a fraction of the size it had grown by 2015. Fixing case inconsistency errors in 2008 was annoying. Fixing them in 2015 was a massive problem we needed to tackle head on. Our source control system’s server was (and is) set to be case insensitive, which means that the two files:
foo/bar.c FOO/baz.c
are in a directory named either foo or FOO (depending on which one was added first). This is just a single directory on Windows and OSX but two distinct ones on Linux. By the time 2015 rolled around, thousands of organically submitted case inconsistencies were present in our source code repository. We developed tooling to detect these inconsistencies, which sounds simple enough, but isn't. First, you need to find all the permutations of the case of a path and see what the preferred case is. Most of the time, it's obvious. These three paths differ only in case, the number of files in the leaf directory is shown to the left:
151 /src/unittest/db/testdata/exceldirectcleaningtests/umu0001/ 3 /src/unittest/db/testdata/ExcelDirectCleaningTests/UMU0001/ 1 /src/unittest/db/testdata/ExcelDirectCleaningTests/umu0001/
One can clearly see that the first permutation is the most common and should be the preferred case. Sometimes it wasn't so obvious and required closer inspection. Tooling could choose the most common permutation automatically, but we were only going to do this once, so we manually inspected every choice, which was very time consuming. Additionally, after the case of the file path was modified, it was also necessary to update any references to those files that existed in code. This could appear anywhere in lots of different types of code, so we had to look carefully at all continuous integration failures on Linux. Many were due to case inconsistencies. The worst part of this entire process was caused by a quirk of our source control system. Our source control system stores the case of filenames as metadata, and changes in case are not integrated from branch to branch. This meant that fixing the case on the parent of all downstream branches and integrating the fixes was not an option. This ultimately meant that we needed to clear the deck of changes for an entire weekend (the Dev team was told to expect that all the branches would be locked) and then simultaneously apply mostly (but not completely) identical case fixes to 16 or 17 branches. Each branch needed 4000+ fixes. The tooling helped, but thank goodness we only had to fix the case once! And the fact that we now build and test the code on Linux prevents case inconsistencies from occurring again.
Symbol visibility, global variables and crashing at exit
Once the code was compiling and linking, it was time to see if it could run. Initial results were mixed. Many test programs or Tableau Server processes ran to completion either successfully or with tractable errors only to crash on exit. Crashing on exit was a huge problem that required many months to fix. In the end it came down to pesky global variables and symbol visibility.
To review, a global variable is one declared outside of any function or class. Two examples are:
int foo = 3; ClassWithDestructor bar;
The first variable, foo, is global and is bad form because generally we try to not use global variables, but it will not cause crashes on exit because it has no destructor. The second variable, bar, can be problematic. If multiple shared objects each link the object file that contains bar, its visibility is unconstrained, and all files are linked into a single executable, then upon exit, each shared object will point at the same piece of memory for bar and will attempt to destruct it. The second attempt will usually result in a double-free crash. Even if there is only a single copy of bar in the entire process, since bar is defined at global scope, it is initialized before main() begins and destructed after main() returns. So when the destructor is executed, it may run arbitrary code that may depend on other structures and pointers that may have already been reset. It was the classic “static initialization order fiasco” resulting in unpredictable crashes.
The first type of crash is fixed by being very disciplined about symbol visibility. If you only take one thing away from reading this article, let it be this: when building a non-trivial C++ project on Linux, pay very close attention to symbol visibility. Do your best to hide as many symbols in as many libraries are you can. And definitely refer to the GCC Visibility wiki frequently.
By default, symbols in Linux C++ compilers are visible. You have to take action to hide them. On the other hand, to even compile code on Windows, you have to set the visibility correctly with __declspec(dllexport) and __declspec(dllimport). On Linux, because the default is that symbols are visible, it's easy to have the same symbol present and visible in multiple libraries that all consume common code and that therefore link correctly but cause problems at runtime.
In our case, a critical change was enabling proper use of the -fvisibility=hidden compiler flag and making the default visibility hidden in concert with the __attribute__((visibility("default"))) compiler option to mark purposely exported symbols as visible. But even this wasn't enough. Our code linked in some static archives, and we found that we were exporting all of the symbols from those static archives, which was absolutely unwanted! Our licensing code failed to run successfully until we added the critical linker flag -Wl,--exclude-libs,ALL which tells the linker to hide all symbols from linked static archives.
The second type of crash is fixed by using “magic static” variables instead of using global variables which you can read about here and here. This allows singletons to be initialized safely at first use which means they are created after main() begins and then can be destructed more easily in an orderly fashion before main() returns.
I very much recommend that even after you do all of this, run nm or readelf over your libraries and look at the list of exported symbols. Is it what you expected? Export as few symbols as possible. Doing so can speed up link time and make your program much more reliable.
Incidentally, these crashes happened on Windows too, but they happened incrementally over a decade and each crash was fixed in a way that worked with the MSVC build tools. Throwing a new compiler and linker at such a massive amount of code just exposed a massive number of issues at once.
Switching to Clang
Even after enabling proper symbol visibility, our Linux programs still crashed in ways that were hard to debug. We were still using g++ but experimenting with Clang because it was more modern, had better support for the latest C++ standard, and was updated more frequently. Ultimately, we switched to using Clang for all of those reasons, but also for two other important reasons. First, the code ran and crashed significantly less. I can't explain why, but it did. Perhaps it was because our OSX build used Clang so the first port to the Mac had already debugged the issues. I’m not certain, but regardless, having both OSX and Linux builds using Clang was nice to have. The second big reason was that the Clang build was twice as fast as the g++ build (12 minutes vs 25 minutes). That's a big deal for developer productivity, as anyone who has waited for a build to complete knows first hand. This also turned out to be more than twice as fast as the Windows build. It was thrilling but also came with an odd downside. When a build error occasionally snuck past pre-validation and was submitted, the Linux CI pipeline was so fast that frequently the branch owners would see the build error on Linux, assume it was a Linux-only problem, and assign the resulting defect to the Linux porting team. If only the branch owners had waited 30 minutes to see the same error on Windows. Switching to Clang gave the Linux team an onslaught of build defects. Be careful what you wish for!
Ship GNU’s C++ runtime
If you poke around the Tableau Server on Linux installer files, you may notice that we ship the GNU C++ standard library (libstdc++) instead of Clang's C++ standard library (libc++). We recognize that it's odd to compile with Clang but ship GNU's C++ library, but we do this for very good reasons. While libc++ is very attractive for the same reasons that Clang is attractive as a compiler, the Clang developers decided to be very strict in how they allow runtime type information (RTTI) across shared object boundaries. When compiling our code with Clang’s libc++, we found that we could not link our code as is because of the strict policies. Dynamic casts do not work the same as with libstdc++ and Windows. libc++ insists that for a dynamic cast to succeed that all types that are in the type tree of a dynamic cast be publicly visible so that there is only a single definition of that type's vtable and typeinfo. libc++ uses a simple pointer compare to determine that types are equal, so if two identical types appear in different shared objects because one or both were hidden, their addresses will be different and the dynamic cast will fail.
A great example in our code of where this fails is any class which is a header-only pure virtual class. Because it's header-only and marked as "hidden," a copy of its vtable and typeinfo appear in every library/binary that references it. Dynamic casts from an object that derives from that class will fail because libc++ sees multiple copies of the typeinfo and vtable, and simple address compares fail. This also fails for the simple case of archived types. One archive defines types that we use in dynamic casts. Because the archive is static, none of its symbols are exported, and those symbols appear in every shared object that reference the archive such that all dynamic casts that reference that type across library boundaries will fail.
Yet because the Windows linker is more lenient, we've followed the pattern of duplicating these types in multiple objects countless times over the years. Clearly, dynamic casts must work so there was really no option but to use libstdc++ as our runtime. For further reading see this great blog post about RTTI using libc++ and this Stackoverflow question and answer about the differences between libstdc++ and libc++ and why the Clang developers chose the behavior they did.
Compiling the code stack
After the C++ code base was running, we focused on porting the rest of the server stack to Linux. Thankfully, everything above C++ on our stack was already designed to be cross-platform and so most things "just worked." Our stack consists of C++ on the bottom with Java as the server layer and any number of web languages that compile to javascript at the top. We use Ruby, Python, and Gradle for tooling. Getting the Java code to compile and run was a process of fixing little problems that would repeat over and over again. It took months to get all the code and tests passing but overwhelmingly the problems stemmed from letter case inconsistencies and file path separators that were hard-coded to backslashes. The biggest challenge in compiling the rest of our stack was handling the C# code base that handles rendering vizzes in a web browser. It's about 100k lines of Windows-only C# code that only comes with a Visual Studio solution file. Porting this code during the Mac port never came up because the code is only part of Tableau Server. I thought it was critical that the Linux build be self-contained and be able to build all the bits necessary to run a server without a dependency on a Windows build machine. To my surprise, compiling C# on Linux and getting the exact same results as compiling it on Windows was possible using The Mono Project. Refactoring was involved (some using the excellent Mono IDE!) because some sub-build tasks couldn't be loaded natively by Mono using Windows DLLs and instead had to be spawned as separate sub-processes, but everything "just worked" after hammering on it for about three weeks. The verification came from comparing build artifacts, which was possible because they were simply javascript text files. We know we did it correctly because the build artifacts are identical. A sincere thanks to the folks who have contributed to the Mono Project!
Holding our breath on image quality
After all this, we still had not seen any visualizations (vizzes) render on Linux. If vizzes didn't look good or took too long to render on Linux, we'd have a major problem. Also, rendering had to be headless (no graphical display). The vast majority of Tableau Servers running on Linux would run in a headless environment, while the vast majority of Tableau Servers on Windows run with a graphical display. While Qt was designed to be very flexible, there was no guarantee that its rendering code would work well with one of their non-graphical display rendering plugins. Also, would the font rendering look acceptable? Font rendering on Windows and Linux are handled by entirely different libraries (fontconfig on Linux vs. native Windows font rendering). Our customers, especially those who planned to convert their Tableau Servers running on Windows to Tableau Servers on Linux would not be happy if vizzes rendering on Linux did not look comparable to the same vizzes on their old Windows servers.
Happily the answer to all these questions was yes. After making sure that fontconfig could find the appropriate fonts, over 75% of all the test images produced on Linux (thousands and thousands of images) were literally identical to the test images produced on Windows. We could use the actual Windows expected test images because they were pixel perfect with the Linux images.
Success!
In February 2016, eight months after the port began, Tableau Server limped to life for the first time. The vizportal web interface worked. Vizzes rendered. Extracts could refresh. The team had grown from one to five. While the server and part of the build and test infrastructure was slowly picking up speed, it would take another five team members and another two years to make Tableau Server ready to ship. In January, 2018, the first version of Tableau Server on Linux was released as part of Tableau v10.5.
Below is a screenshot I took of the very first time I got Tableau Server on Linux to run. Not much to look at, but there it was.
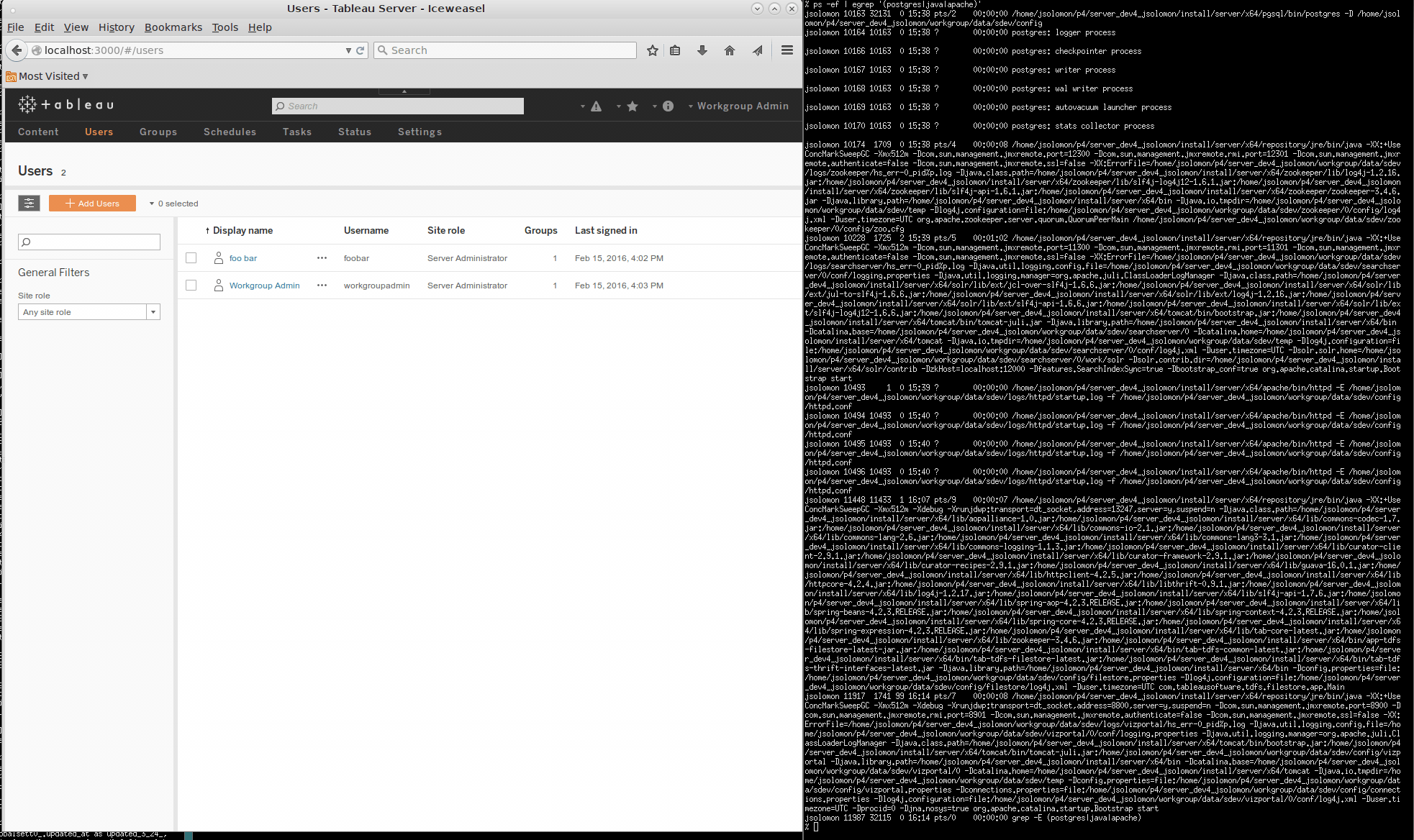
What’s next?
In the next post, we will discuss some of the design choices we made as completed the port of Tableau Server to Linux. Topics include systemd integration, fonts, performance and making sure Tableau Server on Linux was appropriately Linux-y!
Historias relacionadas

Beyond the Default: Customizing Automated Data Insights with GROOT
 24 Octubre, 2024
24 Octubre, 2024

Beyond the Visuals: Elevating Text as a First-Class Citizen in Dashboard Design
 16 Octubre, 2024
16 Octubre, 2024

Exploring Data Uncertainty through Speech, Text, and Visualization
9 Agosto, 2024
Suscribirse a nuestro blog
Obtén las últimas actualizaciones de Tableau en tu bandeja de entrada.