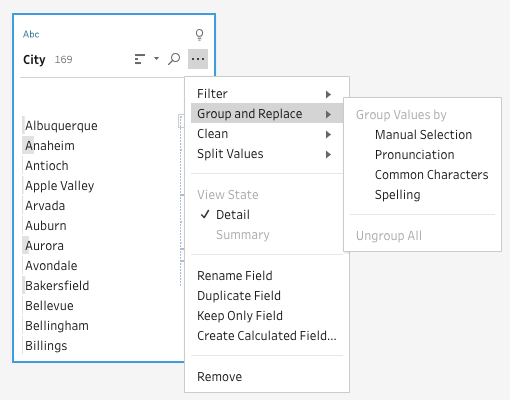
Automated Grouping in Tableau Prep Builder



Text fields in data tables often have data with misspelled values or multiple alternatives of the same concept. For example, a city field with “Seattle” spelled as “Seattel”; an address field with two variations of 5th street as "5th St" and "St, 5th"; or a customer name represented as "First name Last name" and "Last name, First name". To correctly analyze this data, users must manually reconcile data values, which can be error-prone and time-consuming.
John, a Tableau customer, analyzes marketing call data where agents manually enter responses across the US. He finds that users misspell several cities, which leads to errors in his analysis as data is not correctly reported. After spending a lot of time manually fixing the city names, he converted that work to a Python script as he found he has to repeat the standardization with every campaign. Updating this script is still tedious as he works backwards from errors in his analysis. Wouldn't it be great if a data preparation tool could help automate this task?
Automated grouping
To help save our customers time and pain with the task of standardizing data values, the Tableau Prep team developed automated grouping methods to find similar values and group them. Each group is then mapped to the most frequent value in the group. The first version of the Prep product introduced automated grouping with two methods, Pronunciation and Common Characters. Later, we added Spelling.
In Prep, the grouping methods are based on two main techniques: key-based and distance-based. Key-based methods are the fastest but are too strict and result in poor accuracy (items grouped as expected). Distance-based methods, on the other hand, resulted in high accuracy but are too slow due to the quadratic complexity of the algorithm—they compare every string in the data set with every other string. To deliver the best accuracy and performance, we developed a hybrid approach that gets the run time of a key-based method with the accuracy of a distance-based method.
Key-based grouping
In key-based methods like Pronunciation and Common Characters, each value is transformed to a key, or token, and all values with the same key are grouped together.
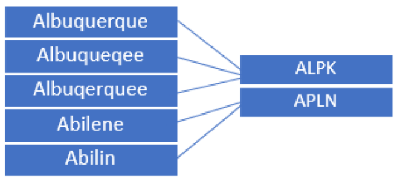
Pronunciation: This method is useful for fixing data entry errors where words sound similar. It uses the Metaphone3 algorithm to generate keys based on the value’s English pronunciation. For example, the values on the left are associated with the keys on the right. The two keys produce two groups of data values:
[“Albuquerque”, “Albuquerqee”, “Albuqerquee”] and [“Abilene”, “Abiline”].
Common Characters: This method is useful to fix capitalization or formatting issues. It tokenizes the value into a character set and sorts the characters to generate a key, known as a 1-gram. In Tableau Prep Builder, this method is case insensitive and only applies to numbers and letters. Before generating the key, each string is first transformed into lowercase letters and all special characters including whitespaces, punctuation, and control characters are removed.
For example, the values on the left are associated with the keys on the right. The two keys generate two groups of data values:
[“James Smith”, “Smith, James”, “Smith James”] and [“Maria, Garcia”, “Garcia, Maria”]
Distance-based grouping
Distance-based methods, like Spelling in Prep, calculate similarity between two strings using the Levenshtein distance. This is the number of edit operations (insertion, deletion, or substitution) required to transform one value into the other. To get a similarity value between 0 and 1, with lower edit distance leading to higher similarity, we use the following normalization for two strings s1 and s2:
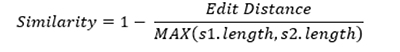
Based on experimentation with some internal datasets, we set a default threshold on Similarity of 0.80 to group values together. For example, let's look at the values “Portland” and “Portand” : the Levenshtein distance is 1 (delete “l” in “Portland” to get “Portand”), so the Similarity will be 0.875 (1 - 1/MAX(8,7)) which is greater than the threshold set. Therefore, “Portland” and “Portand” will be grouped together. Users can adjust the grouping sensitivity by using a slider control that changes this threshold.
Hybrid grouping
When working with large sets of data values, distance-based grouping methods are slow, as they compare all pairs of values. Tableau Prep Builder allows users to directly interact with their data, transform it, get immediate feedback, and confidently prepare data for analysis. So, it’s important to provide users an efficient grouping method that offers good results.
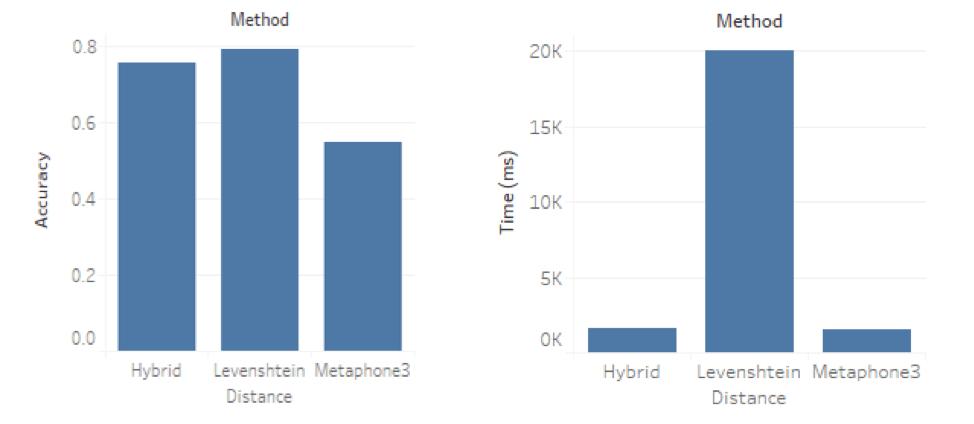
We experimented with using only key-based or distance-based methods to group data where we knew the expected groups (using the geographic data available in Tableau Desktop), and used computation time and accuracy to compare them. We measured accuracy as follows:
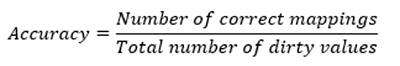
And, we developed a hybrid approach that combined the two methods to produce accuracy like that of Levenshtein distance but at a fraction of the cost (time). The charts show the results of our experiment comparing them using a test dataset.
The hybrid approach transforms data values into their associated keys, then for each key it groups values that are most similar based on distance. Resulting groups are determined based on a similarity threshold.
Let’s walk through an example:
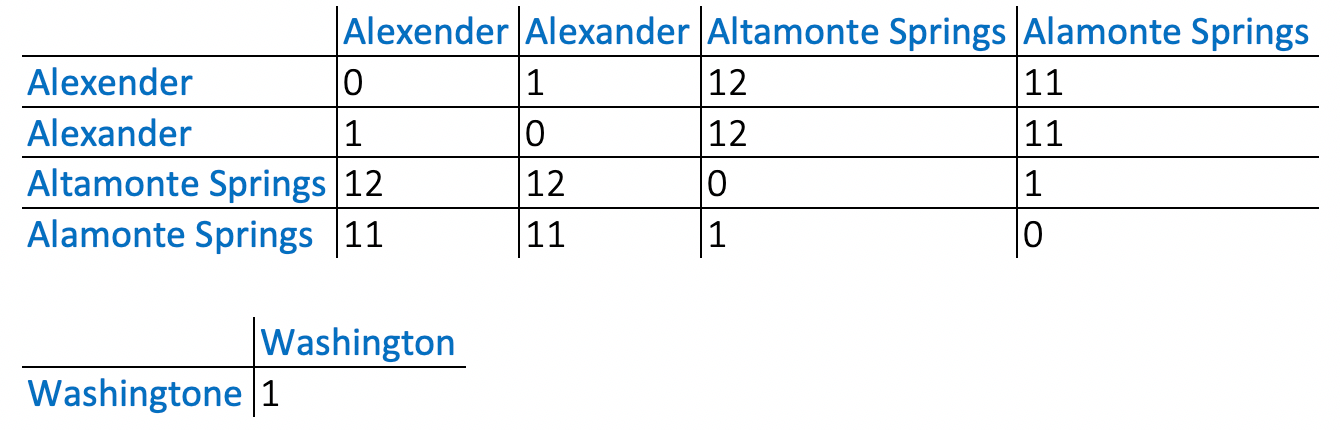
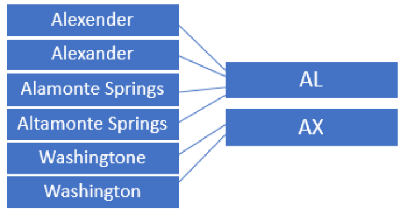
- Transform data values to keys using Metaphone3. For example, the data values on the left are associated with the keys on the right. The two keys produce two groups of data values: [“Alexender”, “Alexander”, “Alamonte Springs”, “Altamonte Springs”] and [“Washingtone”, “Washington”]
- For each key, compute Levenshtein distance and Similarity between values mapped to the key.
Levenshtein distance:
Similarity:
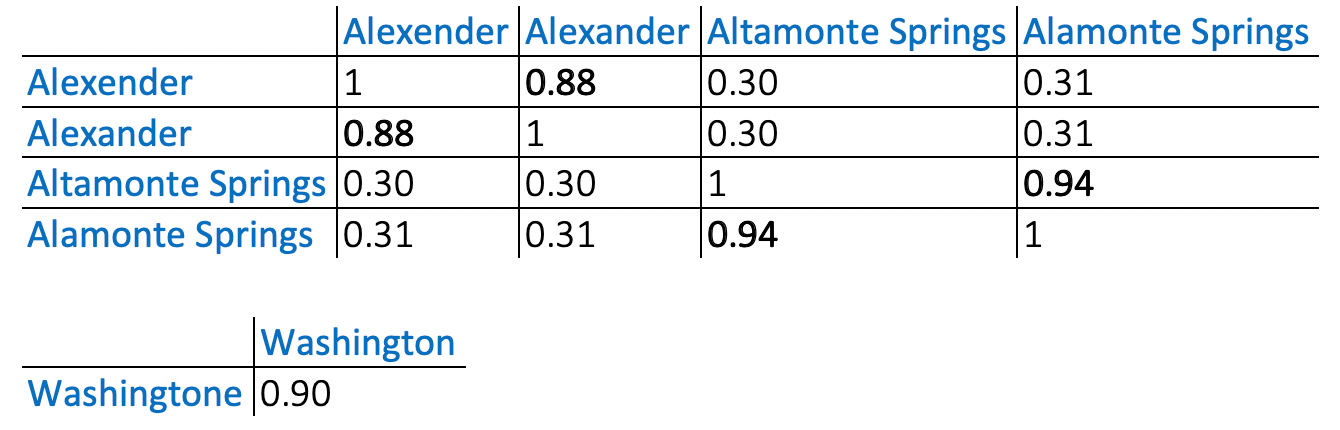
- Use the Similarity threshold (default 0.85 based on internal experimentation) to get the final groups. In the example these are:
[“Alexender”, “Alexander”],
[“Altamonte Springs”, “Alamonte Springs”] and
[“Washingtone”, Washington”]
The Hybrid method is available as “Pronunciation + Spelling” in Tableau Prep Builder 2019.2.3 and later releases. Users can use it on any field with a Data Role applied to map invalid values to valid ones.
Target selection
When field value groups are generated using automated grouping methods, values in the group must be mapped to a single value, the target value. To determine the target, we use the value that appears most frequently in the dataset—usually, this is what users want. If several values have the same frequency, then the target value is selected at random.
With the introduction of Data Roles in Tableau Prep Builder 2018.2.3, users can associate real world meaning to data values to validate and standardize them. These Data Roles offer new context for automated grouping as they define the set of target values, valid values for that Role, particularly ones based on a dictionary of values. For example, data values “Birmingham” and “Birmingam” can be grouped together with “Birmingam” appearing most frequently in the dataset, but with the City role applied, the target for the group will be set to “Birmingham”.
Conclusion
With the hybrid grouping approach and data roles, John can standardize City data in a few clicks – he applies the City data role in Prep Builder to see invalid values and applies the “Pronunciation + Spelling” algorithm to automatically group invalid values to valid ones. This works on most of his data and the easy workflow not only saves him time, but also is easier to update and maintain.
The Tableau Prep team is continuing to automate tedious and core data preparation tasks. Future monthly releases of Prep Builder will have more data standardization improvements, so next time you're faced with a dirty data set and want to save time fixing common data entry errors, give Tableau Prep Builder a try and make cleaning that data a breeze!
Subscribe to our blog
Get the latest Tableau updates in your inbox.