Zwei Methoden für das Crowdsourcing von Daten




Ich verbringe den Großteil des Tages damit, Daten zu visualisieren, die ich von anderen Leuten erhalte. Doch mitunter kommt es ganz anders, als man denkt. Manchmal werden wir ohne Warnung mit Rohdaten überschwemmt und müssen uns ganz schnell einen Reim darauf machen. Oder wir wissen, dass diese Daten eine Geschichte erzählen, aber es gibt keinen Datensatz, in dem alle Fäden zusammenlaufen. Wie geht man als Einzelner damit um, wenn Hunderte (oder Tausende oder gar Millionen) von Datenpunkten zu erfassen sind, bevor mit einer Untersuchung oder Visualisierung begonnen werden kann? Natürlich indem Sie den Datensatz mithilfe von Crowdsourcing generieren.
Einen Datensatz durch Crowdsourcing zu generieren, heißt nichts anderes, als ihn gemeinsam mit anderen zu erstellen. Jeder steuert seine eigenen Datenpunkte bei, um einen Datensatz zu erstellen, den dann andere verwenden können.
Den Hype um den „Marsch der Frauen“, der auf der ganzen Welt stattgefunden hat, habe ich mir zum Anlass genommen, einmal selbst einen Datensatz mithilfe von Crowdsourcing zu erstellen. Ich habe mich gefragt: Welche Hauptanliegen bewegen Menschen dazu, an einem Marsch teilzunehmen? Um das herauszufinden, habe ich eine Umfrage erstellt. Dies ist nur eine Möglichkeit, um Daten durch Crowdsourcing zu erfassen.
Methode 1: Umfragen
Bei näherer Betrachtung ist eine Umfrage ein Instrument, um Daten von Einzelpersonen zu erfassen, die jeweils einen Teil zur größeren Story beisteuern. Wissenschaftler und Akademiker verwenden schon seit Jahrhunderten Umfragedaten. John Snow war einer der Ersten, der uns anhand einer Umfrage in London ein klareres Bild von der Choleraepidemie vermittelt hat. Er hat die Bewohner des betroffenen Gebiets persönlich befragt und die von ihnen mitgeteilten Daten erfasst: wie viele in einem Haus krank sind, wie viele Kranke es gibt, wie lange die Personen schon krank sind ... eben schlicht und einfach alle möglichen Daten.
Streng wissenschaftliche Untersuchungen erfordern eine sorgfältige Prüfung der Umfragen, um Verzerrungen zu entfernen. Aber das heißt nicht, dass eine schnelle informelle Umfrage keinen Wert hätte. Denn Umfragedaten sind es allemal. Und obwohl Umfragen verallgemeinerte Ergebnisse liefern, können diese Verallgemeinerungen dennoch Erkenntnisse enthalten.
Online-Tools wie Google Forms und Survey Monkey gestatten es uns, Umfragen schnell und kostengünstig zu erstellen und verteilen, allerdings treten dabei häufige Fehler auf. Am letzten Wochenende habe ich eine kurze Umfrage aus sechs Fragen in Google Forms erstellt. Ich wollte eine Visualisierung erstellen, die sich aktualisieren würde, wenn Antworten eintreffen. Deshalb habe ich die Fragen kurz gehalten und knappe Antworten formuliert. Ich dachte, ich hätte eine Umfrage zusammengestellt, die einen sauberen, leicht zu visualisierenden Datensatz liefern würde. Da lag ich falsch.
Der Aufbau der Fragen – und die mir zur Verfügung stehenden Umfrageoptionen – waren mein Untergang. Ich habe den Teilnehmern des Marsches der Frauen rund um den Globus die folgenden sechs Fragen gestellt:
- Geben Sie Ihre drei Hauptanliegen für die Teilnahme am Marsch an. (Wählen Sie nicht mehr als drei Optionen aus einer Liste aus, die auch die Option „Sonstiges“ enthält.)
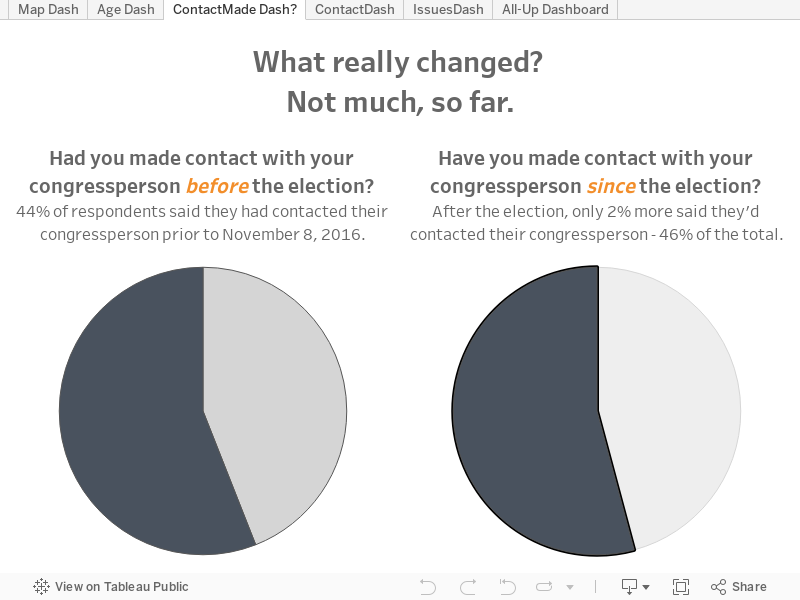
- Haben Sie Ihren Kongressabgeordneten seit der Wahl kontaktiert? (Ja/Nein)
- Welche Methoden haben Sie benutzt, um Ihren Kongressabgeordneten zu kontaktieren, sofern Sie ihn kontaktiert haben? (Wählen Sie so viele Optionen, wie Sie möchten, aus einer Liste aus, die auch die Option „Sonstiges“ enthält.)
- Hatten Sie Ihren Kongressabgeordneten bereits vor der Wahl kontaktiert? (Ja/Nein)
- In welchem Jahrzehnt sind Sie auf die Welt gekommen? (Wählen Sie eine Option aus einer Liste.)
- Wie lautet Ihre Postleitzahl?
Als ich die Tabelle mit den Ergebnissen öffnete, erwartete mich eine Überraschung.
Meine Daten mussten bereinigt werden – und zwar ganz beträchtlich. Warum? Die Fragen 1 und 3 waren das Problem, und natürlich waren das genau die beiden Fragen, die mich am meisten interessierten. Was hatte ich falsch gemacht?
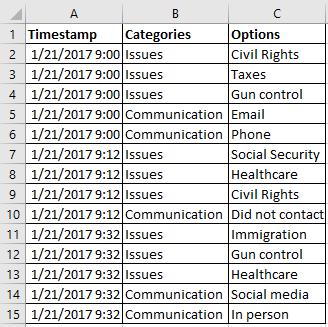
- Fragen mit mehreren Antwortoptionen (wählen Sie alle, wählen Sie bis zu usw.) erzeugen eine einzige Spalte mit Antworten, die durch Kommas oder Strichpunkte getrennt sind. Bevor ich also überhaupt an eine Visualisierung dieser beiden Fragen denken konnte, musste ich die Antworten zunächst in verschiedene Spalten trennen, was zur Folge hatte, dass sich meine Visualisierungen dieser Fragen nicht automatisch aktualisieren würden. (Die Ja-/Nein-Fragen haben dagegen absolut reibungslos funktioniert, genau wie die Fragen nach den Postleitzahlen und den Geburtsjahren.)
- Das Trennen der Antworten in mehrere Spalten verursacht ein weiteres Problem. Das deutet auf eine Sequenz bei der Auswahl hin, d. h. dieses Element wurde als Erstes ausgewählt, dann dieses Element als Zweites und schließlich dieses Element als Drittes. Das heißt, dass der Pfad jedes Befragten einzigartig ist (A, B, C ist nicht dasselbe wie B, C, A). Deshalb konnte ich die Antworten aller Befragten nicht in die am häufigsten gewählten Optionen gruppieren.
- Ich wollte die Hemmschwelle für das Ausfüllen des Fragebogens möglichst niedrig halten, deshalb gab es selbstverständlich auch die Option „Sonstige“. Doch für jemanden, der Daten verarbeitet, ist „Sonstige“ eine schlechte Idee. „Sonstige“ als Option zuzulassen, hieß für mich, dass ich diese Daten ebenfalls in Einklang bringen musste.
Die Lösung für Multiple-Choice-Fragen? Ich musste meine Daten drehen. Anstatt die Daten breit anzuordnen, mit jeder Antwort in einer einzelnen Spalte, musste ich die Daten hoch anordnen und „ähnliche“ Daten in derselben Spalte belassen.
Anstelle hiervon:

Brauchte ich das hier:
Steve Wexler hat einen vorzüglichen Beitrag über das Drehen von Daten in Tableau gepostet, der absolut lesenswert ist.
Wegen der Art und Weise, wie ich die Umfrage aufgebaut hatte, versuchte ich während des Drehens und Analysierens mit Google Forms Live-Daten zu sammeln. Letztendlich habe ich die Daten in einer statischen Datei erfasst, um die Daten zu visualisieren, was nicht ideal war.
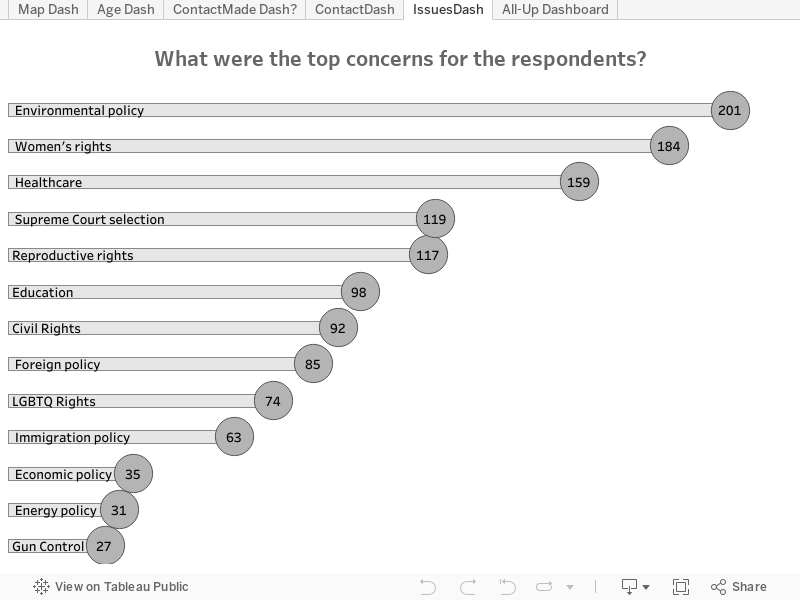
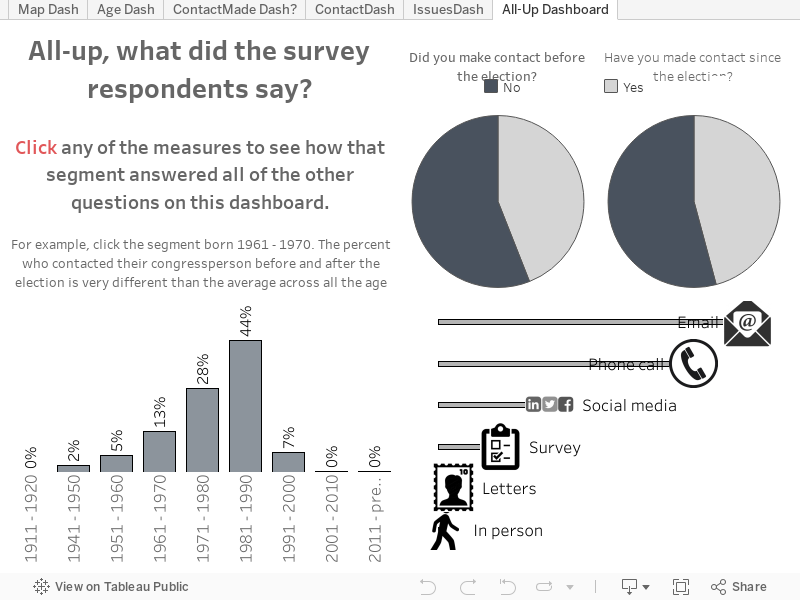
Zu einem viel späteren Zeitpunkt des Projekts hatte ich 456 Antworten zu der Umfrage erhalten (seither sind es allerdings noch mehr geworden). Ich filterte die Probleme mit einzelnen Antworten heraus (dies waren häufig die „sonstigen“ Elemente) und war ein wenig überrascht, dass die Umweltpolitik das dringendste Anliegen der Befragten war. Das könnte vor allem daran gelegen haben, dass der Großteil der Antworten aus dem Pazifischen Nordwesten kam, also aus meiner Heimat.
Meine Visualisierungen sind jetzt vollständig von der Umfrage getrennt, die immer noch Daten sammelt. Darüber bin ich zwar nicht erfreut, aber ich habe eine wichtige Lektion gelernt, nämlich wie die Fragen in einer Umfrage zu strukturieren sind. Nächstes Mal werde ich die Umfrage sogar noch mehr vereinfachen, oder ich werde die folgende Methode verwenden.
Methode 2: Gemeinsame Tabellen
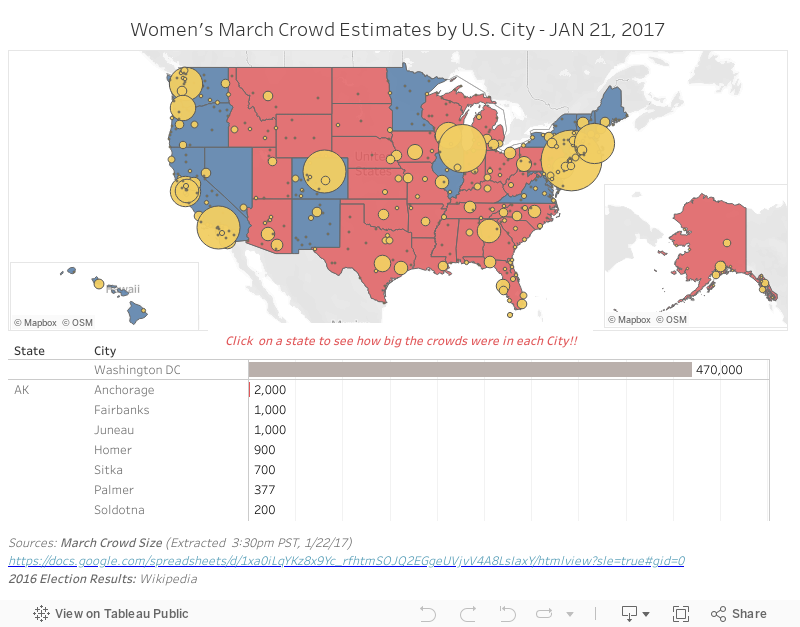
Die zweite Methode, Datensätze per Crowdsourcing zu erstellen, beinhaltet die gemeinsame Nutzung von Tabellen. Das machen wir schon seit den Anfängen des Internets, doch erst in den letzten Jahren ist das richtig in Mode gekommen. Zu gleichen Zeit, als ich Daten mit meiner Umfrage sammelte, haben Erica Chenoweth (@EricaChenoweth) und Jeremy Pressman (@djpressman) ein gemeinsames Google Sheet mit einigen ganz einfachen Anweisungen erstellt. Sie fragten nach den geschätzten Teilnehmerzahlen bei den Märschen am 21. Januar 2017. Es gab einfache Anweisungen: Geben Sie die Zahlen zusammen mit der Stadt, dem Bundesstaat (sofern zutreffend), dem Land und der überprüfbaren Quelle der Daten an. Sie haben die Tabelle in den sozialen Medien bereitgestellt – und dann nahm alles seinen Lauf. Menschen aus aller Welt haben Daten hinzugefügt, und in weniger als 24 Stunden hatten sie einen Datensatz, den jeder nutzen konnte.

War das die perfekte Grundlage für eine Visualisierung? Nein, aber es war kurz und schmerzlos und hat den unmittelbaren Zweck erfüllt. Innerhalb von 24 Stunden hatte ich bereits jemanden bei Tableau Public getroffen, der genügend Daten bereinigte, um sie zu visualisieren und die Wahlergebnisse darunter zu präsentieren. Ich habe noch nicht erlebt, dass die Medien Daten so schnell erfassen, doch Leute, die mit Daten herumspielen, haben das geschafft.
Das Gespräch fortsetzen
Einer der größten Vorteile beim Crowdsourcing von Daten besteht darin, dass Sie das Interesse wecken, denn jeder trägt etwas bei. Fachleute, Anbieter offener Daten und Datenexperten arbeiten zusammen, um Menschen wie mir dabei zu helfen, Daten eingehend zu untersuchen.
Welche per Crowdsourcing gesammelten Daten und durchgeführten Projekte haben Sie bereits erlebt? Welche Vor- und Nachteile haben solche Daten? Ich arbeite bereits an meinem nächsten Datensatz, der mithilfe von Crowdsourcing erstellt wird. Lassen Sie uns also dieses Gespräch fortsetzen!
Zugehörige Storys

Learn the Basics of Well-Structured Data
 6 Dezember, 2024
6 Dezember, 2024

How To Spot Misleading Charts: Review the Message
 24 Oktober, 2024
24 Oktober, 2024

How To Spot Misleading Charts: Check the Axes
17 Oktober, 2024
Blog abonnieren
Rufen Sie die neuesten Tableau-Updates in Ihrem Posteingang ab.