Wir präsentieren: Unterstützung für benutzerdefinierte R- und Python-Skripts in Tableau Prep-Schemas




Neuigkeiten: Die neueste Version von Tableau ist da! Untersuchen Sie die neuesten Innovationen in dieser Version.
Tableau Prep Builder ist ein leistungsfähiges Tool zum Untersuchen und Vorbereiten von Daten. Die Komplexität der von Nutzern erstellten Schemas variiert erheblich. Prep Builder ist für viele Anwendungsfälle sofort startbereit, doch es gibt auch komplexere Szenarien, die nicht so einfach zu konfigurieren sind.
Um diese Lücke zu schließen und noch mehr faszinierende Interaktionsmöglichkeiten mit Tableau Prep bereitzustellen, unterstützen wir jetzt die Ausführung benutzerdefinierter Python- und R-Skripts direkt aus Tableau Prep-Schemas. Dieses Feature befindet sich momentan in der Betaphase für unsere kommende Tableau-Version 2019.3.
Benutzer können ihre Skripts in jedem beliebigen Schritt im Schema verknüpfen und den vollen Funktionsumfang ihrer bevorzugten Skriptsprache nutzen, um die Daten umzuwandeln, zusätzliche Informationen in Remote-Quellen zu suchen oder sogar komplexe Machine Learning-Pipelines zusätzlich zu den Eingaben auszuführen.
Fügen Sie Ihren Tableau Prep-Schemas jederzeit ein benutzerdefiniertes R- oder Python-Skript hinzu.
In diesem Beitrag erkläre ich an einem Beispiel, wie Prep Builder für die Ausführung von Python-Skripts konfiguriert wird. Außerdem zeige ich einige tolle Möglichkeiten, wie Sie diese neue Funktionalität einsetzen können – zum Beispiel für die Durchführung geografischer Suchen.
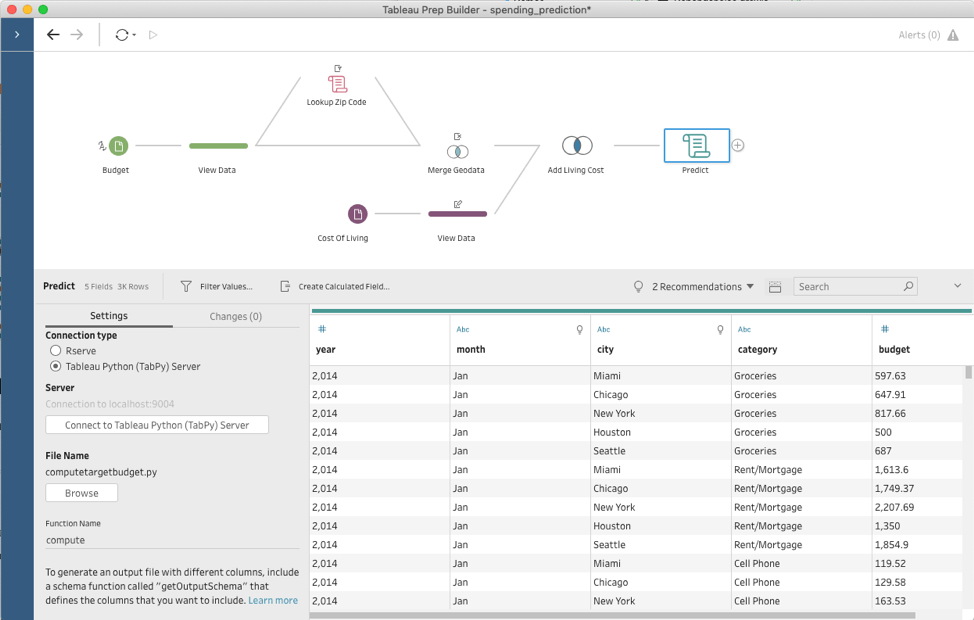
Für die Untersuchung von „Was wäre, wenn“-Szenarien können Sie jede Art von benutzerdefinierten Skripts verwenden. Aber in meinem konkreten Beispiel möchte ich die Daten zu den Lebenshaltungskosten an verschiedenen Orten der USA vergleichen und eine Prognose erstellen, wie sich ein Umzug in eine andere Stadt auf mein Budget auswirken würde. Das Schema, das ich erstelle, beruht auf Budgetdaten, die ich über die letzten Jahren erhoben habe, auf Lebenshaltungskosten und auf der Zuordnung von Postleitzahlen zu Städten.
Einrichtung von TabPy
Tableau Prep Builder nutzt das Open-Source-Tool TabPy für die Ausführung von Python-Code. Da die Skriptausführung eine fortgeschrittene Funktion ist und die Benutzer-Setups stark variieren, ist TabPy in Prep Builder nicht vorkonfiguriert. Aber keine Sorge! Die Einrichtung ist wirklich einfach – hier erfahren Sie, wie es geht. Wenn alles erwartungsgemäß konfiguriert ist, wird ganz unten eine Portnummer für die Verbindung mit dem TabPy-Server angezeigt. Der Standardwert ist „9004“.
Wie alle anderen Sprachen profitiert auch Python enorm von Drittanbieter-Bibliotheken, die den Funktionsumfang erweitern. Für Prep muss die Bibliothek „pandas“ installiert sein, da diese einen effizienten Datenrahmen bereitstellt, mit dem wir Daten an und von Python übergeben können. Die Installation ist kinderleicht und basiert auf dem Tool „pip“, das zum Lieferumfang von Python gehört. Für mein Budgetproblem brauche ich auch eine Bibliothek namens „requests“, also installiere ich beide Bibliotheken, indem ich
> pip install pandas requests
ausführe und den TabPy-Server neu starte. Wann immer Sie weitere Bibliotheken für Python benötigen, können Sie sie mit „pip“ und einem anschließenden Neustart von TabPy installieren.
Jetzt habe ich alles konfiguriert und kann mich auf die Lösung für mein Problem konzentrieren.
Ausführen einer geografischen Suche
Für die Prognose meiner Kosten in verschiedenen Städten ziehe ich den Lebenshaltungskostenindex zurate. Dieser Index beschreibt die relative Kostspieligkeit einer Stadt als Prozentsatz im Vergleich zu New York City, das einen Wert von 100 hat. Da meine Rohdaten für das Budget nicht Städte, sondern Postleitzahlen enthalten, muss ich diese zunächst konvertieren. Ich nutze die Python-Integration, um programmgesteuert zu jeder Postleitzahl die Stadt zu suchen.
Hierzu muss ich nur einen Skriptschritt hinzufügen, diesen auf eine Python-Skriptdatei verweisen und in dieser Datei den Namen der aufzurufenden Funktion angeben. Prep Builder sendet alle Eingabedaten aus dem vorherigen Schritt an TabPy und ruft diese Funktion mit den Daten als Argument auf. Anschließend zeigt Prep Builder den im Skriptschritt zurückgegebenen Datensatz an.
Sehen wir uns das jetzt an meinem konkreten Beispiel der Postleitzahlenkonvertierung an. Dies ist die Skriptdatei:
import requests API_KEY = "" URL = f'https://www.zipcodeapi.com/rest/{API_KEY}/info.json' def lookup(df): result = pd.DataFrame(columns=['zip_code','city', 'state','area']) for zip in df['zip_code'].unique(): response = requests.get(f'{URL}/{zip}/radians').json() zip_code = response['zip_code'] city = response['city'] state = response['state'] result = result.append({ 'zip_code' : zip_code, 'current city' : city, 'state' : state }, ignore_index=True) return result def get_output_schema(): return pd.DataFrame({ 'zip_code' : prep_string(), 'current city' : prep_string(), 'state' : prep_string() });
In der Skriptdatei sind zwei Funktionen definiert: „lookup“ und „get_output_schema“.
Die „lookup“-Funktion ist der Kern der Ausführung und sorgt für die eigentliche Datenumwandlung. Dies ist die Funktion, die wir in der Prep Builder-UI konfigurieren. Sie nimmt als Eingabe den „pandas“-Datensatz und verwendet die Spalte „zip_code“, um Stadt und Bundesstaat aus zipcodeapi.com abzufragen. Das Ergebnis ist ein weiterer „pandas“-Datensatz mit drei Spalten: die ursprüngliche Postleitzahl, die aktuelle Stadt und der Bundesstaat. Beachten Sie, dass wir keine der anderen Spalten in der Eingabe verwenden. Sofern die Spalte „zip_code“ vorhanden ist, funktioniert das Skript problemlos, ungeachtet der sonstigen Daten.
Durch die zweite Funktion, „get_output_schema“, soll Prep Builder die zu erwartenden Daten als Ausgabe des Skripts interpretieren. Wenn Sie sich das Skript genau ansehen, stellen Sie fest, dass es einen „pandas“-Datenrahmen mit denselben Spalten wie die „lookup“-Funktion zurückgibt, aber mithilfe von Werten wie „prep_string()“ den zu erwartenden Datentyp an Prep Builder übergibt. Natürlich werden auch andere Datentypen unterstützt, zum Beispiel „prep_int()“ oder „prep_bool()“.
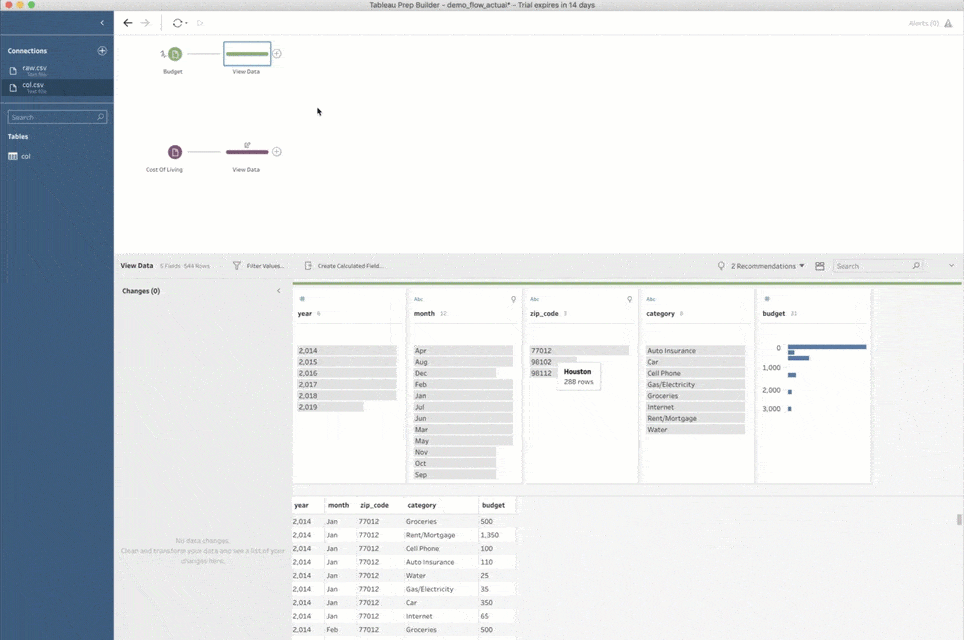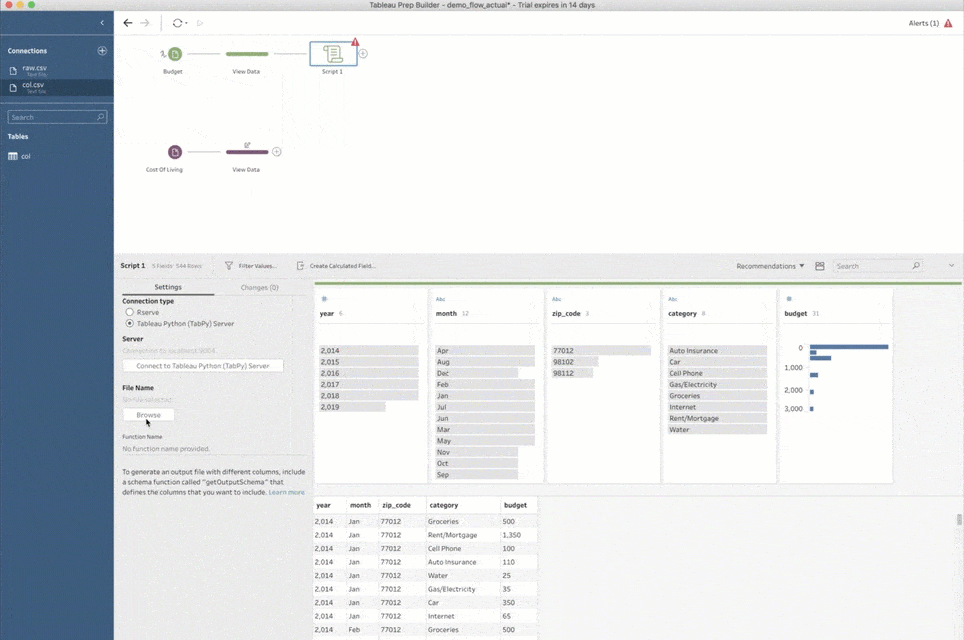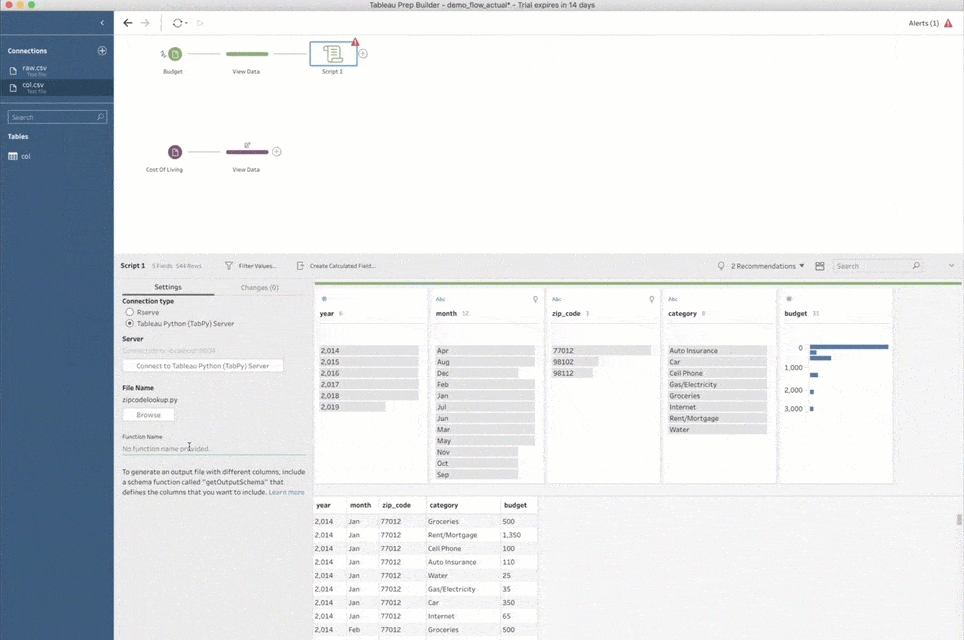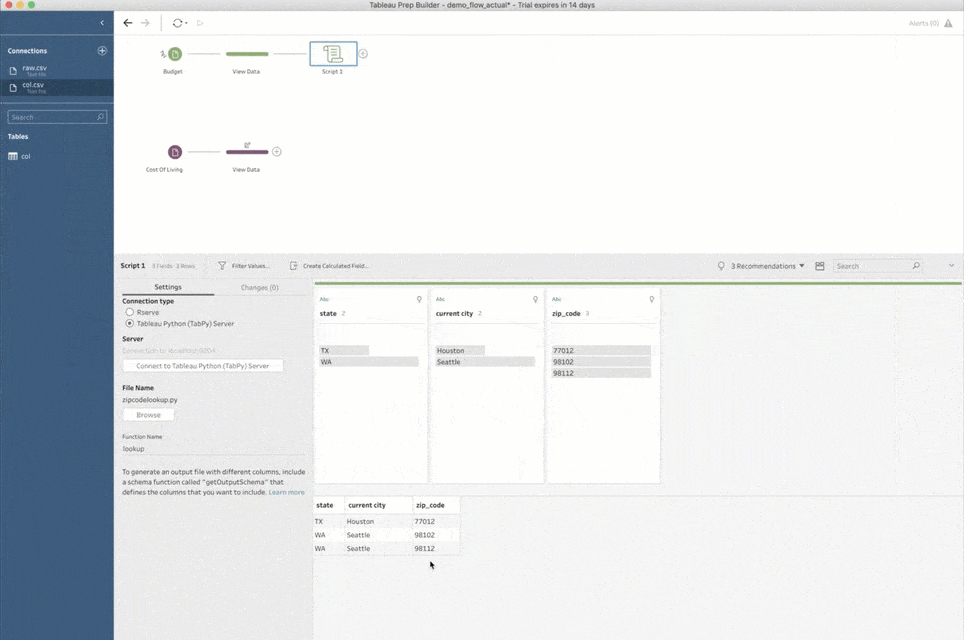
Noch eine Anmerkung: Wenn Sie einem Schema zum ersten Mal einen Skriptschritt hinzufügen, müssen Sie Prep Builder mitteilen, wie die Verbindung mit TabPy erfolgen soll. Wählen Sie hierzu den Verbindungstyp „Tableau Python (TabPy) -Server“ und klicken Sie auf „Verbinden zu Tableau Python (TabPy) -Server“. Geben Sie im Popup-Fenster den Servernamen und die Portnummer für die TabPy-Instanz an. Für ein lokales Setup wie oben verwenden Sie als Server „localhost“ und als Portnummer „9004“.
Vorbereiten des Datenbestands für die Prognosemodellierung
Mit dem Skript aus dem vorherigen Abschnitt ist es extrem einfach, meinen Budgetdaten die korrekten Städte und Bundesstaaten zuzuordnen. Durch Verknüpfung der Skriptausgaben mit den ursprünglichen Eingaben werden die Daten zusammengeführt und können weiterverarbeitet werden.
Bevor ich allerdings meine Ausgaben prognostizieren kann, muss ich die Daten für die Lebenshaltungskosten hinzufügen. Es gibt vergleichbare APIs für das Abrufen solcher Informationen, diese sind aber nicht kostenlos verfügbar. Daher verwende ich eine statische CSV-Datei, die die erforderlichen Daten enthält. Wenn Sie Zugriff auf APIs haben, die Informationen dieser Art abrufen können, sollten Sie diese natürlich verwenden – wie bei der Postleitzahlensuche.
Die mir verfügbaren Daten enthalten lediglich den Städtenamen, den zugehörigen Lebenshaltungskostenindex und das Jahr, in dem die Daten erfasst wurden. Ich habe für fünf Städte Daten für den Zeitraum zwischen 2014 und 2019 erhoben. Diese Stichprobe sollte ausreichen, um meine Fragen zu beantworten.
Da ich Budgets für mehrere Städte, aber auf der Grundlage von Daten für einen bestimmten Zeitpunkt prognostizieren möchte, ergibt sich zwangsläufig eine Eins-zu-N-Beziehung. Für jeden Datensatz meines Budgetdatenbestands gibt es eine Entsprechung für jede „Ziel“-Stadt und deren Index für jedes Jahr, in dem die Budgeteinträge erstellt wurden. Dies kann in Prep Builder ganz einfach mit einem Inner Join dargestellt werden.
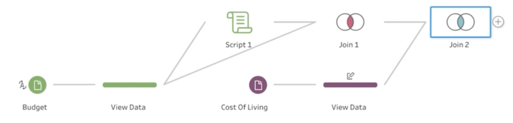
Der Schemabereich bietet eine visuelle Darstellung der Datenvorbereitungsschritte.
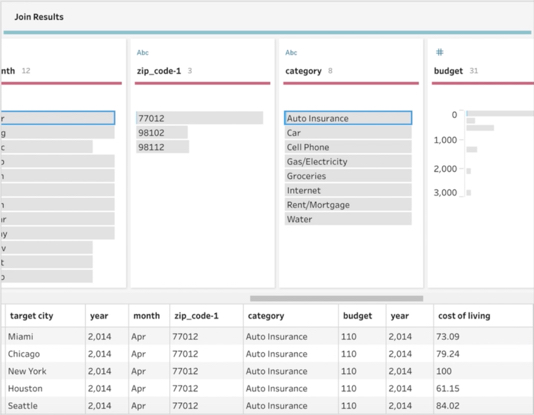
Der Profilbereich und das Datenraster zeigen das Ergebnis des Inner Joins.
Prognostizieren meiner Ausgaben
Jetzt habe ich alle Daten zusammengeführt und kann meine potenziellen Ausgaben prognostizieren. Die exakte Logik hierfür kann erheblich variieren – von einer einfachen Berechnung bis hin zu komplizierten Machine Learning-Modellen, die meine Budgetdaten analysieren und auch leichte Abweichungen in meinem Konsumverhalten über die Zeit berücksichtigen. Doch in jedem Fall ist Python eine große Hilfe bei dieser Aufgabe. Es ermöglicht nicht nur komplexe Datentransformationen, sondern bietet fantastische Bibliotheken zum Erstellen ausgefeilter Machine Learning-Pipelines. Ich kann einfach ein weiteres Skript erstellen und damit anhand meines gesamten Datenbestands meine Ausgaben prognostizieren. Und auch wenn diese Aufgabe und das Skript nun ziemlich anders aussehen, so ist das Verfahren, mit dem ich dies alles in Prep Builder einrichte, mit dem identisch, das ich für die Suche nach den Postleitzahlen verwendet habe.
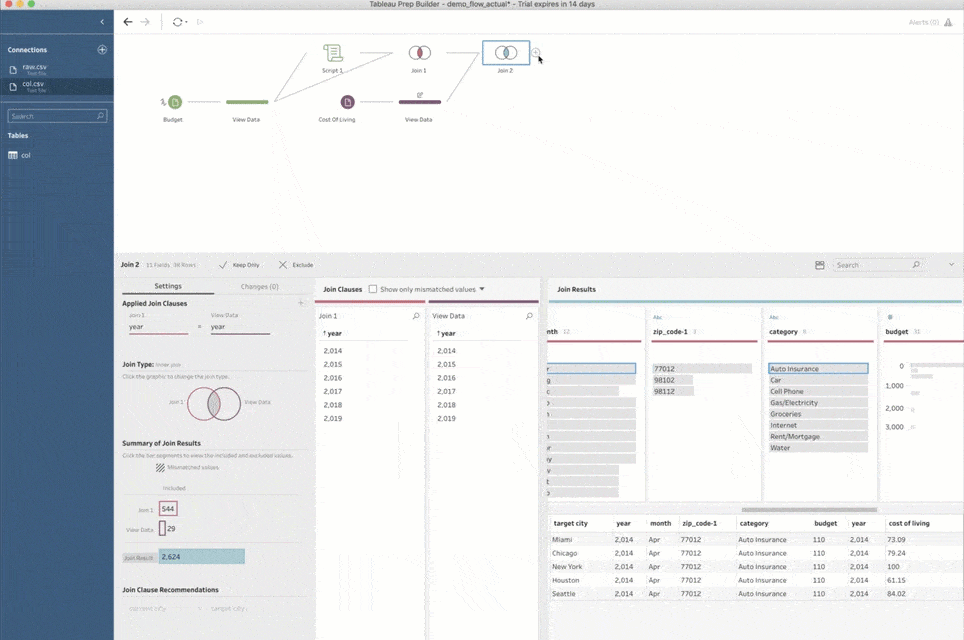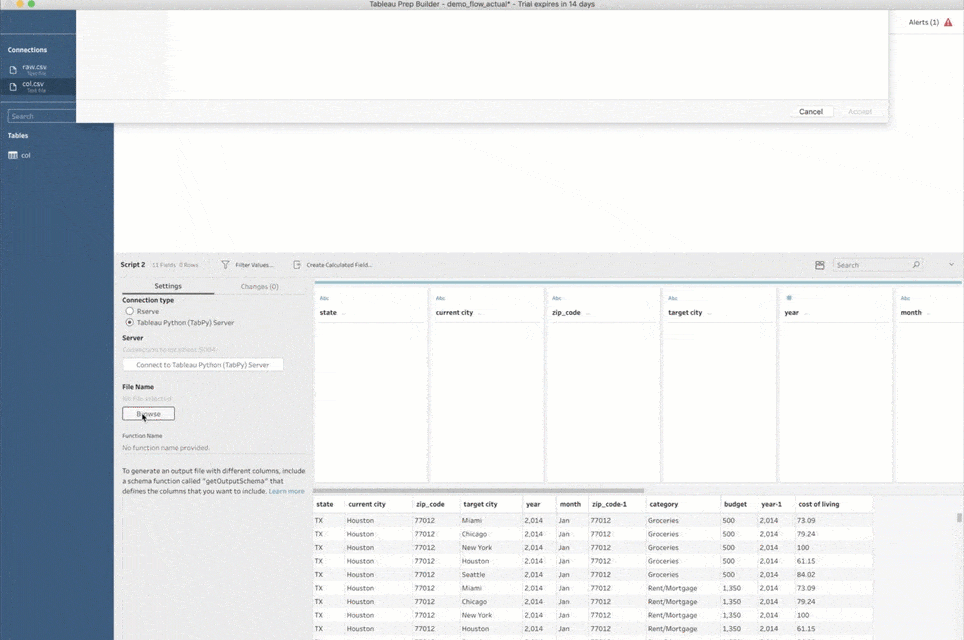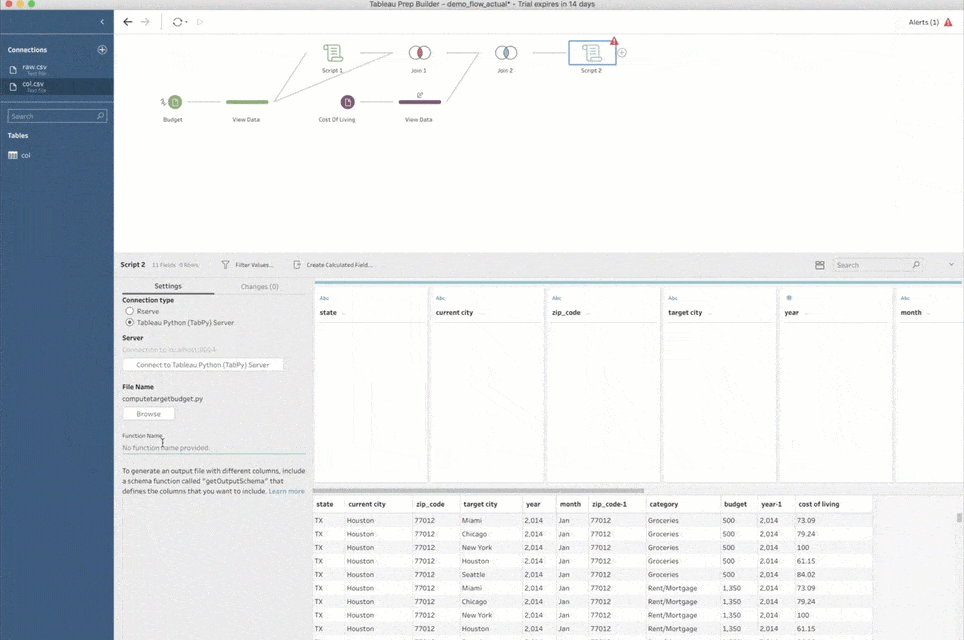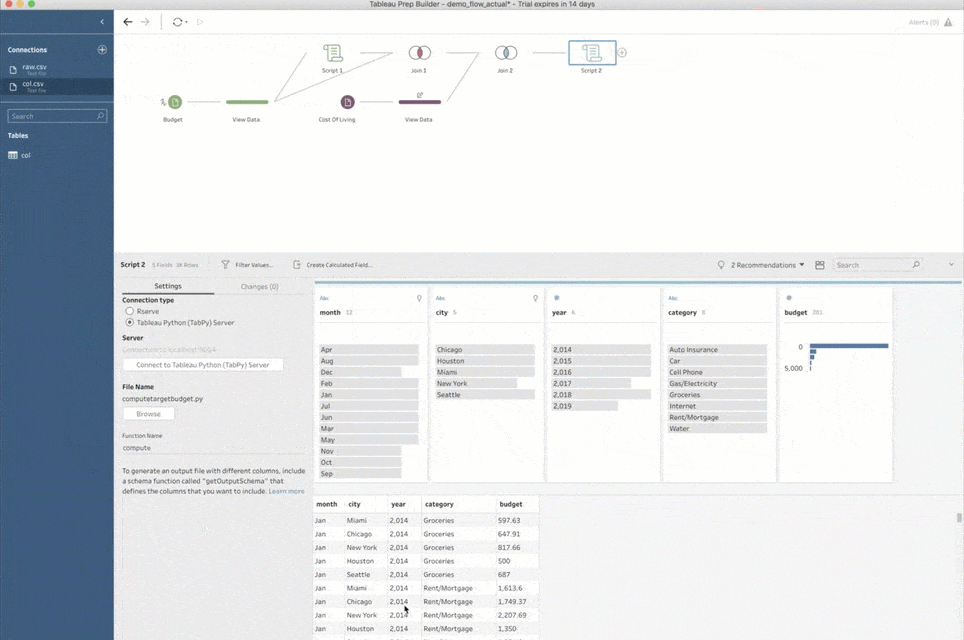
Dann kann ich eine Ausgabedatenquelle erstellen und die Ergebnisse meiner Prognosen auf Tableau Server veröffentlichen. Noch beeindruckender ist, dass ich das resultierende Schema ganz einfach als Prep Conductor-Job planen kann, um meine Machine Learning-Pipeline in regelmäßigen Abständen zu aktualisieren!
Zur Klarstellung: Sie können zwar Ergebnisse unter Tableau Online veröffentlichen, die Ausführung von Schemas, die Skripts enthalten, mit Tableau Prep Conductor wird jedoch in Tableau Online noch nicht unterstützt.
Fazit
Mit dieser neuen Unterstützung zur Skripterstellung in Prep Builder ist es jetzt einfacher denn je, komplexe Szenarien für die Datentransformation zu implementieren, die weit über die integrierten Funktionen des Produkts hinausgehen. Dies reicht von einfachen Berechnungen bis zu komplexen Machine Learning-Modellen und dem Datenabruf aus dem Internet.
Noch befindet sich diese Funktionalität in der Betaphase, doch wir erhalten äußerst positive Rückmeldungen aus unserer Community. Die Nachfrage nach Unterstützung benutzerdefinierter Skripts ist enorm, da immer mehr Benutzer aus unterschiedlichsten Bereichen ihre eigenen Snippets erstellen, um Prep Builder noch effektiver zu nutzen. Ich bin begeistert von dieser Integration und ich hoffe, dass ich Ihnen zeigen konnte, wie einfach Sie Ihre eigenen Python-Skripts erstellen und in Tableau Prep integrieren können.
Wenn Sie Ihre eigenen Ideen ausprobieren und die Python- und R-Integrationen in unserer 2019.3 Betaversion in Aktion sehen möchten, nehmen Sie an unserem Pre-Release-Programm teil.
Zugehörige Storys

What to Know About Tableau Next: FAQ
 7 April, 2025
7 April, 2025

Tableau 2025.1 Release Now Available: VizQL Data Service API, Tableau Cloud Release Preview Sites, and More

VizQL Data Service: Extend Your Data Beyond Visualizations
 19 März, 2025
19 März, 2025
Blog abonnieren
Rufen Sie die neuesten Tableau-Updates in Ihrem Posteingang ab.